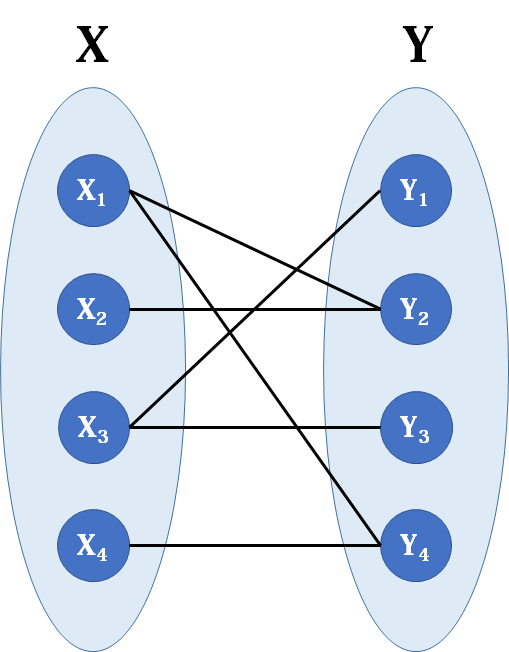
#include <iostream> #include <string.h> #include <stdio.h> using namespace std; const int maxn=200010;//边数的最大值 //参考资料https://zhuanlan.zhihu.com/p/96229700; //整理的笔记:https://tyler-ytr.github.io/2021/04/13/%E5%8C%88%E7%89%99%E5%88%A9%E7%AE%97%E6%B3%95/ //邻接链表定义 struct Edge { int to,next; }edge[maxn]; //to 是该边指向的点 next表示源点为x的下一条边,这是遍历以x为源点的关键 int head[maxn],tot;//tot当前的边的数量;head[x]表示以x为源点的第一条边,初始值为-1 void init() { tot=0; memset(head,-1,sizeof(head)); }//初始化函数 void addedge(int u,int v) { edge[tot].to=v;//对边进行编号 edge[tot].next=head[u];//将U这个点上一次连接的点记录如果没有即为-1 head[u]=tot++;//等于边的编号,之后edge[head[u]]即可调用这个边 }//加边函数 //匈牙利算法 int match[maxn];//记录当前右侧元素所对一个的左侧元素 bool vis[maxn];//记录当前右侧元素有没有被访问过 int N;//左侧元素的数量 bool dfs(int u){//dfs左侧元素 for (int i=head[u];i!=-1;i=edge[i].next){//顺着边过去,一直遍历和这个点连接过的点和边;-1是邻接链表的最后 int v=edge[i].to; if(!vis[v]){ vis[v]=true;//记录状态为访问过 if(match[v]==-1||dfs(match[v])){//如果暂无匹配,或者原来匹配的左侧元素可以找到新的匹配 match[v]=u;//当前左侧元素成为当前右侧元素的新匹配 return true;//返回匹配成功 } } } return false; }
int Hungarian(){ int res=0; memset(match,-1,sizeof(match)); for(int i=0;i<N;++i){ memset(vis,false,sizeof(vis)); if(dfs(i))++res; } return res; }
int main(){ //X为左侧,Y为右侧 int M; cin>>N>>M; //printf("%d\n",N); int tempnum; int tempy; int j=0; init(); for(int i=0;i<N;i++){ //cin>>tempnum; scanf("%d",&tempnum); //printf("%d\n",tempnum); for (j=0;j<tempnum;j++){ //cin>>tempy; scanf("%d",&tempy); addedge(i,tempy); } } //建图完毕 int result = Hungarian(); printf("%d\n",result); return 0; }