RDMA技术整理2 RDMA概述
RDMA背景
TCP/IP通信
使用传统的TCP/IP通信,数据需要通过用户空间发送到远端的用户空间,就需要经历若干次内存拷贝。
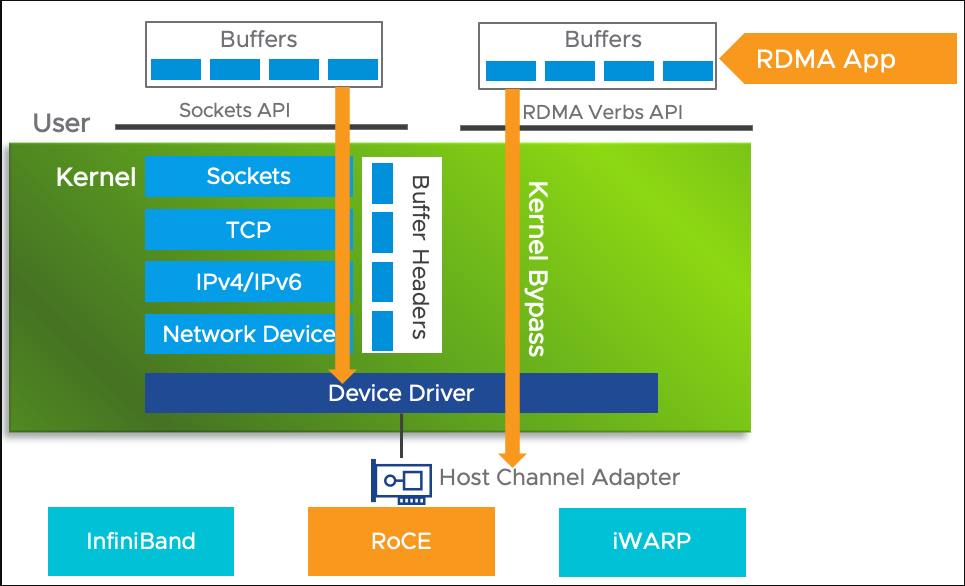
- 数据发送方需要讲数据从用户空间 Buffer 复制到内核空间的 Socket Buffer
- 数据发送方要在内核空间中添加数据包头,进行数据封装
- 数据从内核空间的 Socket Buffer 复制到 NIC Buffer 进行网络传输
- 数据接受方接收到从远程机器发送的数据包后,要将数据包从 NIC Buffer 中复制到内核空间的 Socket Buffer
- 经过一系列的多层网络协议进行数据包的解析工作,解析后的数据从内核空间的 Socket Buffer 被复制到用户空间 Buffer
- 这个时候再进行系统上下文切换,用户应用程序才被调用
这就带来了高速网络环境下面,TCP/IP在主机侧数据移动和复制操作的高开销,影响了带宽。
针对这个问题提出了多种解决方案,主要介绍如下两种:
- TCP offloading engine
- RDMA
TCP offloading engine
这个技术主要就是把CPU进行的多层网络协议数据包处理工作,比如数据复制、协议处理和中断处理等等操作转移到支持offloading的网卡上。如下图所示
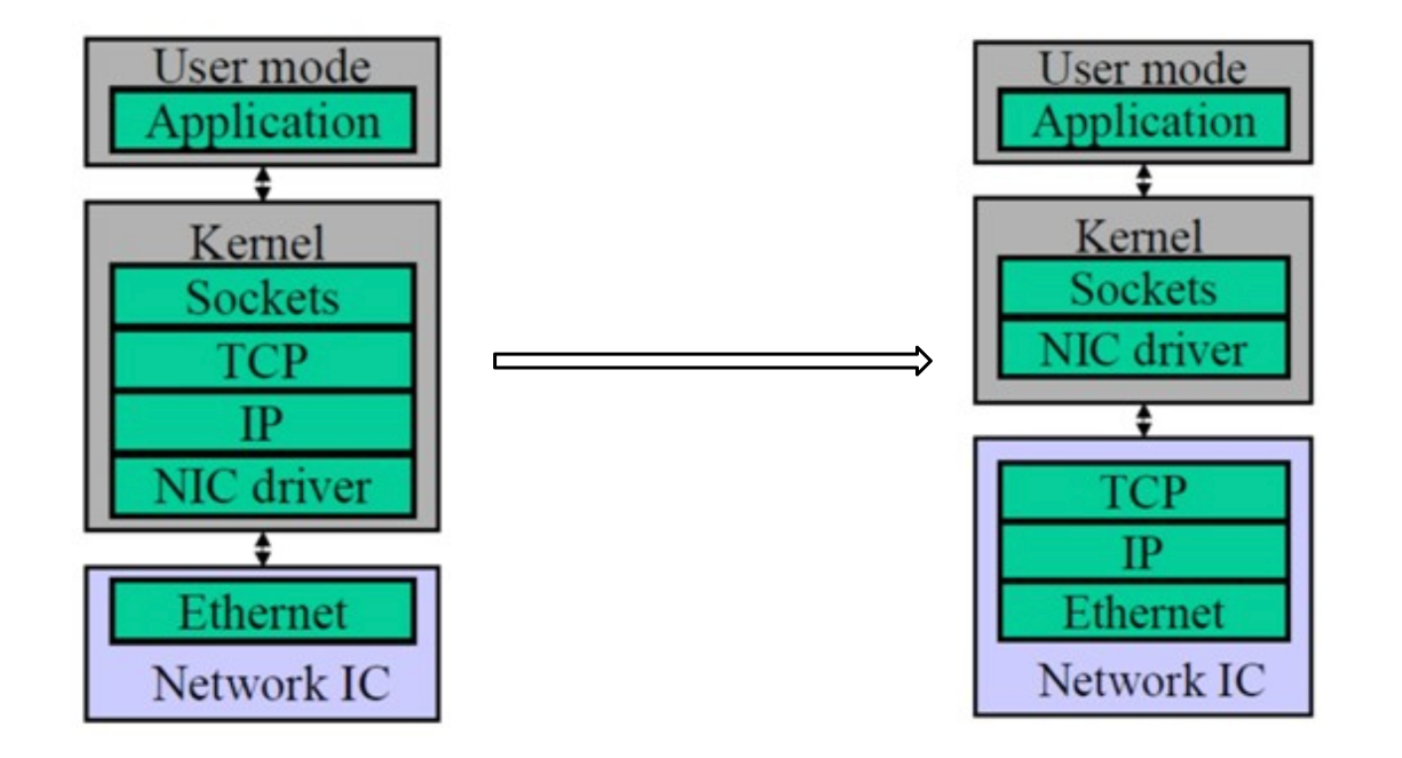
- TOE(TCP offloading engine)技术将原来在协议栈中进行的IP分片、TCP分段、重组、checksum校验等操作,转移到网卡硬件中进行
- 普通网卡处理每个数据包都要触发一次中断,TOE 网卡则让每个应用程序完成一次完整的数据处理进程后才触发一次中断,显著减轻服务器对中断的响应负担。
- TOE 网卡在接收数据时,在网卡内进行协议处理,因此,它不必将数据复制到内核空间缓冲区,而是直接复制到用户空间的缓冲区,这种“零拷贝”方式避免了网卡和服务器间的不必要的数据往复拷贝。
RDMA
RDMA的目的是更快更轻量级的网络通信,利用了Kernel Bypass和Zero Copy技术的低延迟特性,减少了CPU占用和内存带宽瓶颈。对外RDMA提供了基于IO的通道,允许一个应用程序通过RDMA设备对远程的虚拟内存进行直接的读写。它的整体架构图如下:
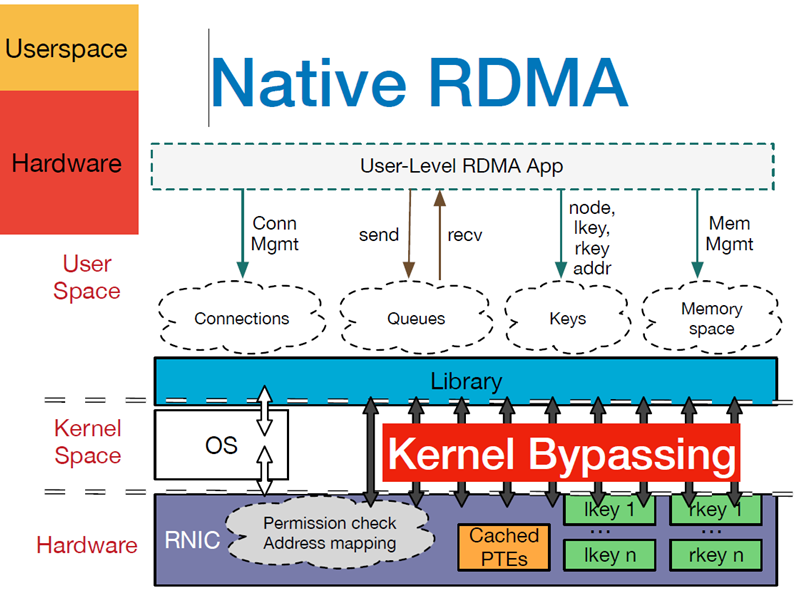
RDMA技术有以下特点:
- CPU Offload:无需CPU干预,应用程序可以访问远程主机内存而不消耗远程主机中的任何CPU。远程主机内存能够被读取而不需要远程主机上的进程(或CPU)参与。远程主机的CPU的缓存(cache)不会被访问的内存内容所填充
- Kernel Bypass:RDMA 提供一个专有的 Verbs interface 而不是传统的TCP/IP Socket interface。应用程序可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换
- Zero Copy:每个应用程序都能直接访问集群中的设备的虚拟内存,这意味着应用程序能够直接执行数据传输,在不涉及到网络软件栈的情况下,数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被复制到网络层。
RDMA架构
目前主要有三种硬件实现,可以使用同一套API:
- Infiniband:基于 InfiniBand 架构的 RDMA 技术,由 IBTA(InfiniBand Trade Association)提出。搭建基于 IB 技术的 RDMA 网络需要专用的 IB 网卡和 IB 交换机。从性能上,很明显Infiniband网络最好,但网卡和交换机是价格也很高,然而RoCEv2和iWARP仅需使用特殊的网卡就可以了,价格也相对便宜很多。
- iWARP:Internet Wide Area RDMA Protocal,基于 TCP/IP 协议的 RDMA 技术,由 IETF 标 准定义。iWARP 支持在标准以太网基础设施上使用 RDMA 技术,而不需要交换机支持无损以太网传输,但服务器需要使用支持iWARP 的网卡。与此同时,受 TCP 影响,性能稍差。
- RoCE:基于以太网的 RDMA 技术,也是由 IBTA 提出。RoCE支持在标准以太网基础设施上使用RDMA技术,但是需要交换机支持无损以太网传输,需要服务器使用 RoCE 网卡,性能与 IB 相当。
下面以Infiniband技术为例介绍它的分层架构:
这部分来自于前面的博客以及Introduction to InfiniBand
Infiniband分层与架构
Inifiniband包含了多种设备,channel adapter、switch、router、subnet manager,它提供了一种基于通道的点对点消息队列转发模型,每个应用都可通过创建的虚拟通道直接获取本应用的数据消息,无需其他操作系统及协议栈的介入。Channel adapter是安装在主机或者其他任何系统(如存储设备)上的网络适配器,这种组件为数据包的始发地或者目的地;Switch包含了多个InfiniBand端口根据每个数据包 LRH 里面的 LID,负责将一个端口上收到的数据包发送到另一个端口。Router根据 L3 中的 GRH,负责将 Packet 从一个子网转发到另一个子网,当被转到到另一子网时,Router 会重建数据包中的 LID。Subnet Manager负责配置本地子网,使其保持工作。
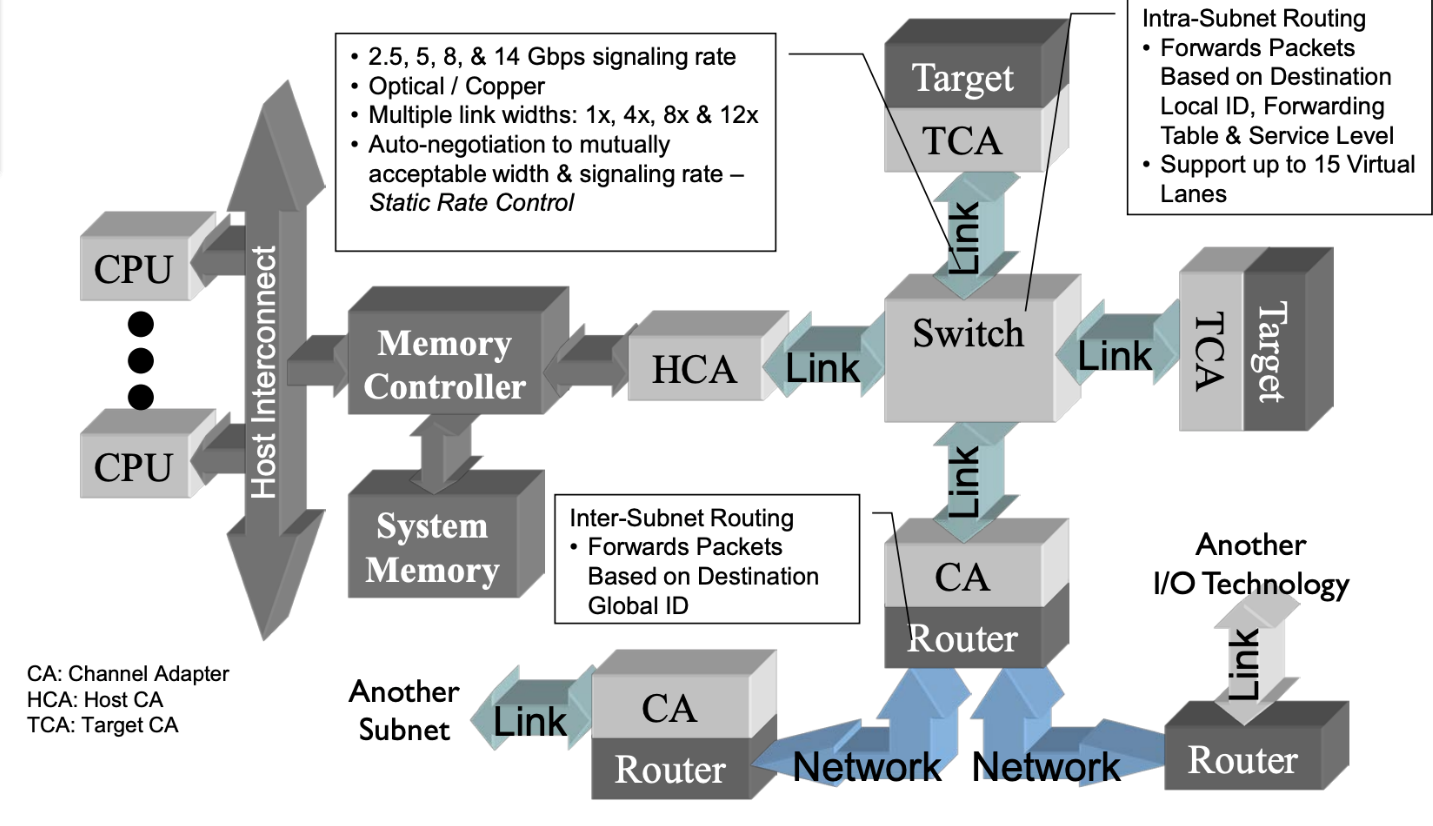
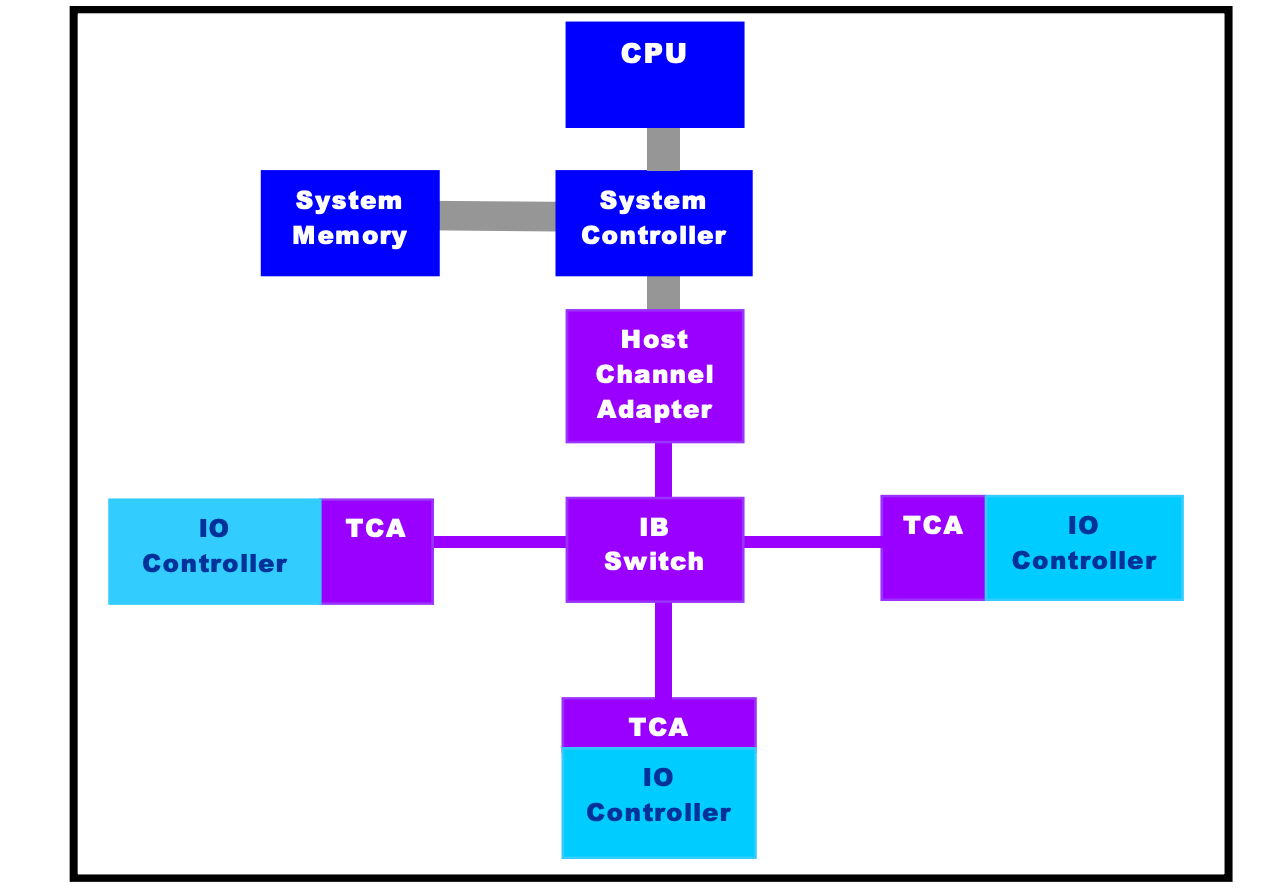
InfiniBand 有着自己的协议栈,从上到下依次包括传输层、网络层、数据链路层和物理层:
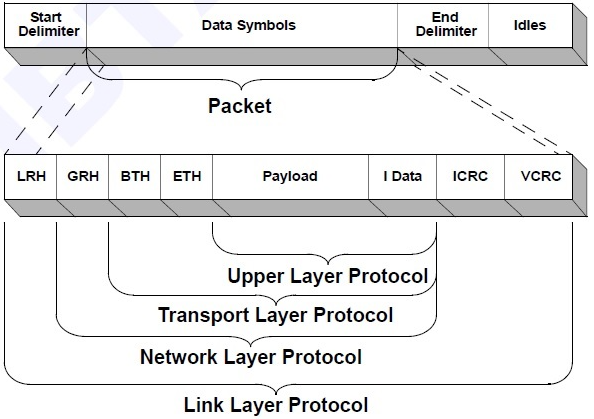
如上图是数据包的封装。
物理层
物理层支持光线和铜,绝大多数采用4 Link;
链路层
这部分是架构的核心,包含了如下部分:
- Packets:链路层由两种类型的Packets,Data Packet 和 Management Packet,数据包最大可以为 4KB,数据包传输的类型包括两种类型
- Memory:RDMA read/write,atomic operation(其实就是内存操作)
- Channel:send/receive,multicast transmission
- Switching:在子网中,Packet 的转发和交换是在链路层完成的
- 一个子网内的每个设备有一个由 subnet manager分配的 16 bit Local ID (LID)
- 每个 Packet 中有一个 Local Route Header (LRH) 指定了要发送的目标 LID
- 在一个子网中通过 LID 来负责寻址
- Qos:链路层提供了 QoS 保证,不需要数据缓冲
- Virtual Lanes:一种在一条物理链路上创建多条虚拟链路的机制。虚拟通道表示端口的一组用于收发数据包的缓冲区。支持的 VL 数是端口的一个属性。
- 每个 Link 支持 15 个标准的 VL 和一个用于 Management 的 VL15,VL15 具有最高等级,VL0 具有最低等级
- Service Level:InfiniBand 支持多达 16 个服务等级,但是并没有指定每个等级的策略。InfiniBand 通过将 SL 和 VL 映射支持 QoS
- Credit Based Flow Control:发送数据包之前,发送方和接收方需要协商数据量credit,接收方保证有足够的Buffer,之后传输才能进行。
- Data Integrity:链路层通过 Packet 中的 CRC 字段来进行数据完整性校验,其组成包括 ICRC 和 VCRC。

网络层
网络层负责将 Packet 从一个子网路由到另一个子网:
在子网之间发送的数据包包含全局路由标头 (GRH)。GRH 包含数据包源和目标的 128 位 IPv6 地址。数据包通过基于每个设备的 64 位全局唯一 ID (GUID) 的路由器在子网之间转发。路由器在每个子网中使用正确的本地地址修改 LRH。因此,路径中的最后一个路由器将 LRH 中的 LID 替换为目标端口的 LID。
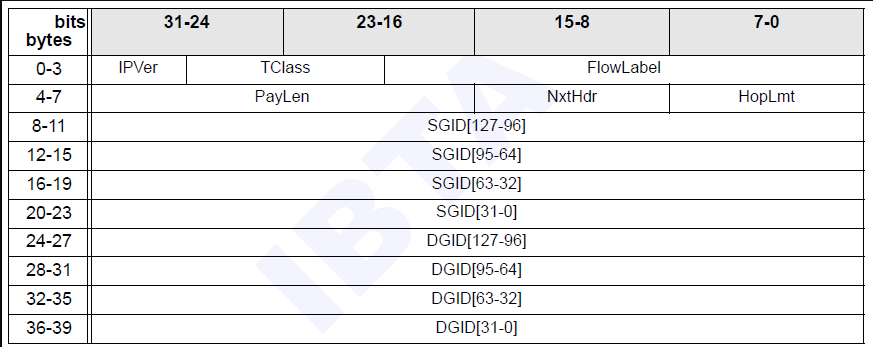
下面是 GRH 报头的格式,长40字节,可选,用于组播数据包以及需要穿越多个子网的数据包。它使用 GID 描述了源端口和目标端口,其格式与 IPv6 报头相同。
传输层
传输层负责 Packet 的按序传输、根据 MTU 分段和很多传输层的服务(reliable connection, reliable datagram, unreliable connection, unreliable datagram, raw datagram)。InfiniBand 的传输层提供了一个巨大的提升,因为所有的函数都是在硬件中实现的。
RDMA技术相对于传统技术
在技术整理1中介绍了DMA的知识;RDMA与DMA相似,它的含义是远程直接地址访问;通过RDMA,本端节点可以“直接”访问远端节点的内存。所谓直接,指的是可以像访问本地内存一样,绕过传统以太网复杂的TCP/IP网络协议栈读写远端内存,而这个过程对端是不感知的,而且这个读写过程的大部分工作是由硬件而不是软件完成的。
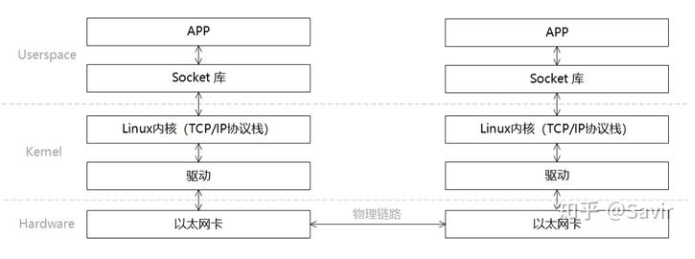
在传统的以太网socket通信中,一次收发过程如下:
- 发送端和接收端通过Socket库提供的接口建立链接(就是在两个节点间建立了一条逻辑上的道路,数据可以沿这条道路从一端发送到另一端)并分别在内存中申请好发送和接收Buffer。
- 发送端APP通过Socket接口陷入内核态,待发送数据经过TCP/IP协议栈的一层层封装,最后被CPU复制到Socket Buffer中。
- 发送端通过网卡驱动,告知网卡可以发送数据了,网卡将通过DMA从Buffer中复制封装好的数据包到内部缓存中,然后将其发送到物理链路。
- 接收端网卡收到数据包后,将数据包放到接收Buffer中,然后CPU将通过内核中的TCP/IP协议栈对报文进行层层解析,取出有效的数据。
- 接收端APP通过Socket接口陷入内核态,CPU将数据从内核空间复制到用户空间。
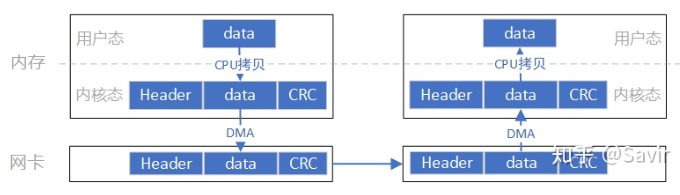
因此数据相当于如上图流向,需要从用户空间复制到内核空间(CPU)然后网卡从内核空间把处理好的数据从物理链路发送到对端网卡;对端网卡过程相似。
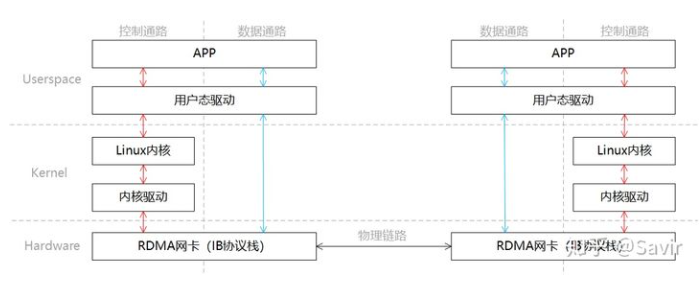
RDMA把模型分成了两部分,一部分是控制通路一部分是数据通路,控制通路需要进入内核态准备通信所需的内存资源,而数据通路指的是实际数据交互过程中的流程。具体的通信过程如下:
- 发送端和接收端分别通过控制通路陷入内核态创建好通信所需要的内存资源。
- 在数据通路上,接收端APP通知硬件准备接收数据,告诉硬件将接收到的数据放在哪片内存中。
- 在数据通路上,发送端APP通知硬件发送数据,告诉硬件待发送数据位于哪片内存中。
- 发送端RDMA网卡从内存中搬移数据,组装报文发送给对端。
- 对端收到报文,对其进行解析并通过DMA将有效载荷写入内存。然后以某种方式通知上层APP,告知其数据已经接受并且存放到指定位置
具体的数据流向如下:
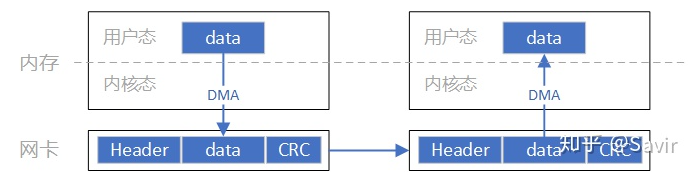
可以看出这部分减少了CPU的参与,报文的组装和解析通过硬件而不是CPU完成。这就是RDMA技术的优势所在。
