概括
本文介绍了发生在CPU和网卡之间通过PCIe来传输信息和基于Inifiniband互联发送完成信号的一系列协调事件
正文
在Inifiband上面发送信息的传统方法是通过Verb API. libibverbs是这个API的标准实现,目前由Linux-RDMA社区维护。
Verbs可以分为两类:慢速和快速函数( slow-path and fast-path functions)
Slow-path 函数比如ibv_open_device, ibv_alloc_pd等等与创建或者配置资源(比如Context, Protection Domain, and Memory Region)有关,他们慢的原因是因为这部分涉及内核,因此会产生昂贵的上下文开销。
Fast-path函数比如ibv_post_send, ibv_poll_cq处理操作的初始化或者完成,他们快的原因是因为他们绕过了内核,因此相对于slow-path的那些函数要快。
通信的关键路径由fast-path函数构成,偶尔包括slow-pathhanshu ,比如用ibv_reg_mr来动态注册内存(取决于通信中间件)。
这篇文章主要介绍程序员执行ibv_post_send之后的机制
PCIe的简要背景
网卡通过PCIe(PCI Express)插槽连接到服务器。Root Complex 简称RC,是CPU和PCIe总线之间的接口,他把处理器和内存连接到PCIe。连接到PCIe末端结构的外围设备成为PCIe端点。
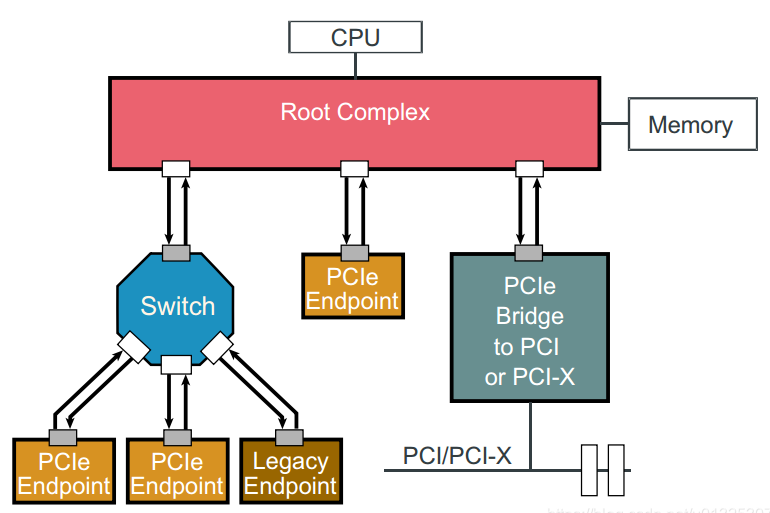
PCIe协议由三层组成:事务层,数据链路层和物理层(the Transaction layer, the Data Link layer, and the Physical layer);
最上层也就是事务层描述事务发生的类型;对于本文而言两种类型的事务层包(Transaction Layer Packets (TLPs))是相关的:MemoryWrite (MWr), and Memory Read (MRd). 与独立的MWr TLP不同,MRd TLP与来自目标 PCIe端点的数据完成事务耦合,完成事务包含了发起方请求的数据;
数据链路层保证了所有事务的成功执行,主要是基于数据链路层包确认(Data Link Layer Packet (DLLP) acknowledgements (ACK/NACK)) 以及基于信用的流控机制(a credit-based flow-control mechanism);只要发起方有足够的信用额度就可以发送事务,当它从邻居收到更新的流控制的数据链路层包(DLLP)的时候就会补充信用;这种流控机制允许PCIe协议具有多个未完成的事务。
基本机制
首先,本文描述如何使用完全卸载(completely offloaded)的方法来发送消息,也就是CPU只通知网卡有信息要发送,网卡会执行其他所有操作来传输数据。在这种方法中,CPU对于计算活动更加可用,然而这种方法不利于小消息传输的性能,为了提高这种情况下的通信性能,Infiniband提供了一些下一节讲描述的操作特性。
从CPU程序员的角度来看,存在一个传输队列(the send queue in Verbs is the Queue Pair (QP))以及一个完成队列(long for CQ in Verbs)。用户发布消息描述符(MD;Verbs里面的工作队列元素WQE)到传输队列,之后他们在CQ上面轮询来确认已经发布的消息的完成。用户还可以请求收到有关完成的终端通知。但是轮询的方法是延迟导向的( latency-oriented),因为在关键路径上没有到内核的上下文切换。
如下图,通过网络传输信息是通过处理器和网卡之间的协调进行的,使用内存映射I/O(MMIO)和直接内存访问(DMA)读取和写入。
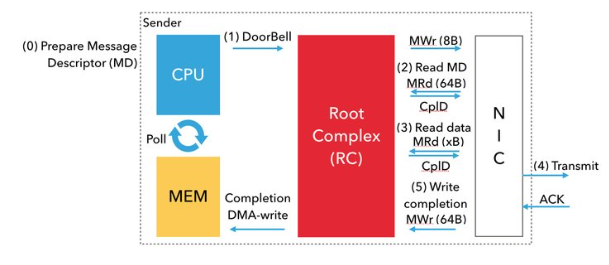
步骤如下:
- 用户首先把MD排队进入TxQ,然后网络驱动程序准备特定于设备的MD,其中包含网卡的头以及指向有效负载的指针
- CPU(网络驱动程序)使用8字节的原子写入内存映射位置,通知网卡消息已经准备好发送,这成为doorbell。RC使用MWr PCIe事务来执行doorbell。
- doorbell响起之后,网卡通过DMA读来获取MD。主要通过MRd PCIe事务 来执行DMA读取。
- 然后网卡使用另一个DMA读取(另外一个MRd TLP)来从注册的内存区域里面获得有效负载。注意必须先将虚拟地址转换成物理地址,网卡才能够执行DMA读取。
- 一旦网卡接收到负载,他会通过网络传输读取的数据,成功传输之后网卡会接受目标网卡的确认ACK。
- 收到ACK之后,网卡用DMA写(使用MWr TLP)写入完全队列条目(CQE,在Mellanox InfiniBand中为64字节)到与TxQ关联的CQ。然后CPU将轮询到此完成。
总而言之,每一个post的关键路径需要一次MMIO写入,两次DMA读取和一次DMA写入。DMA读取实际上是往返的PCIe延迟比较昂贵,比如ThunderX2机器上的往返PCIe是125 纳秒。
Operational features 优化小消息通信
Postlist,内联(inlining),无信号完成(unsignaled completions)以及可编程I/O( Programmed I/O )是IB的操作功能(operational features),有助于减少上述开销。下面描述中假设QP的深度为n。
- Postlist: IB不是每一个
ibv_post_send只发布一个WQE,而是允许应用程序发布WQE的链接列表,这只需要调用一次ibv_post_send,从而把n次Doorbell的开销降低到1. - Inlining: CPU(网络驱动程序)将数据复制到 WQE 中。因此,通过对 WQE 的第一次 DMA 读取,NIC 也获得了有效负载,从而消除了对有效负载的第二次 DMA 读取。
- Unsignaled completions: 如果每n个WQE至少有一个是发出信号的,IB就允许应用程序关闭WQE的完成,而不是为每一个WQE发送完成信号。关闭完成操作可以减少网卡的CQE的DMA写入。另外,应用程序轮询的CQE更少,这减少了开销。
- BlueFlame: BlueFlame是Mellanox对编程I / O的术语 - 它将WQE与门铃一起写入,切断WQE本身的DMA读取。请注意,BlueFlame 仅在没有 Postlist 的情况下使用。使用Postlist,NIC将对链表中的WQE进行DMA读取。
为了减少PCIe往返延迟的开销,开发者一般对小的消息使用inlining和blueflame,它可以消除两个PCIe往返延迟。Postlist和unsignaled completions的使用主要依赖于用户的程序设计选择和应用程序的语义。
具体代码实现小消息通信优化
在ibv_post_send中的wr中利用IBV_SEND_INLINE和IBV_SEND_SIGNALED进行优化;
IBV_SEND_SIGNALED
参考:
