linux文件系统
内核文件表
inode 对于硬盘文件的表述
- inode包含的部分:
- 必须包含:
- mode
- size
- reference count
- block addresses
- 可选:
- timestamps(atime,ctime,mtime)
- uid/gid
- minor/major device numbers
- 不包含:
- file name
- 必须包含:
文件描述符
linux的逻辑中,不同进程具有
task_struct,task_struct中包含file_struct,用于表明进程打开的多个文件,file_struct中包含了file,里面有用于表明file的引用计数的原子变量f_count,表明位置的f_pos等以及inode变量f_inode;逻辑关系(linux 2.6.13)如下图: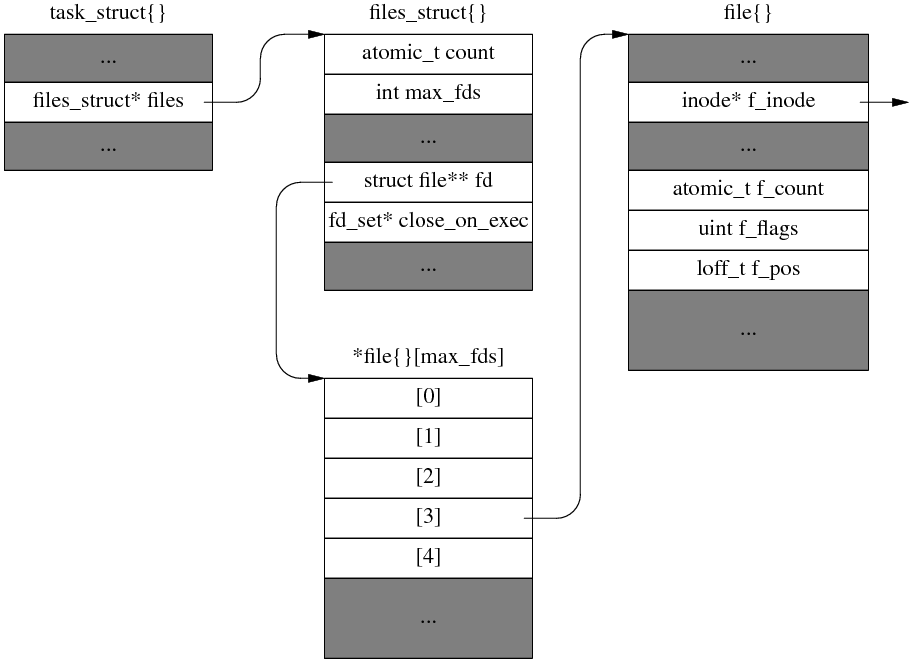
目前的版本把file_struct中的fd二维数组解耦到了新的fdtable也就是file descripter table中;
unix的文件描述分为三层:
- file descripter table (file descripter flags 比如FD_CLOEXEC,表示该文件描述符在执行exec后会被自动关闭;FD_NONBLOCK:表示该文件描述符是非阻塞的(non-blocking),即读取或写入操作不会阻塞进程。) dup[2]不会保留flag
- file entry table(w/r file offset) (file status flags 比如O_NONBLOCK 用于表示该文件表示非阻塞,读取或写入操作将立即返回,而不会等待数据就绪或写入完成。) dup[2]/fork[2]会保留flag值
- inode table
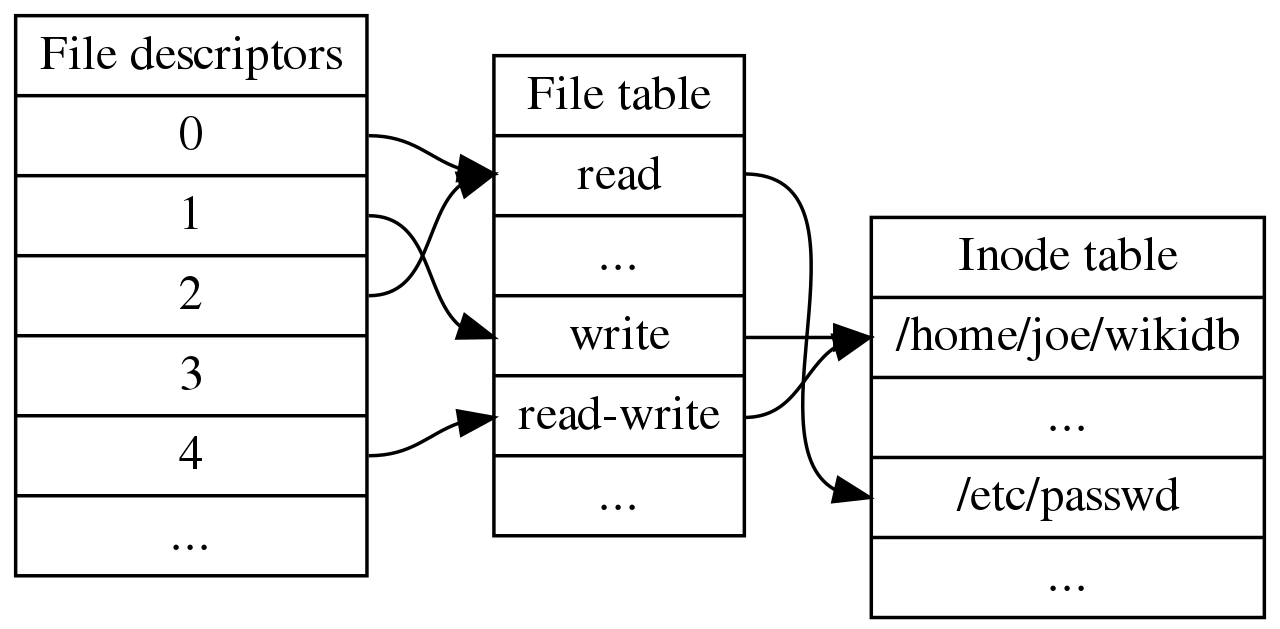
两次open vs open之后dup/fork:
- file descripter table是每一个进程有一个的; file table和inode table是全局的
- file current offest 在 file table里面;file current size在inode table里面
- 如果一个文件open两次,那么会有两个file table entries,每一个FD有自己的offset;
- 如果open之后再dup,那么会有一个file table entry,它的引用计数是2,相当于两个file descripter(FD) 指针指向同一个文件(inode的引用计数是1);
- 如果是open之后再fork,那么会有两个FD指针指向同一个file table entry,inode的引用计数还是1;它们共享相同的offset;(和dup基本一致,只不过file descriptors在不同进程中)
inode
ext2文件系统的inode:
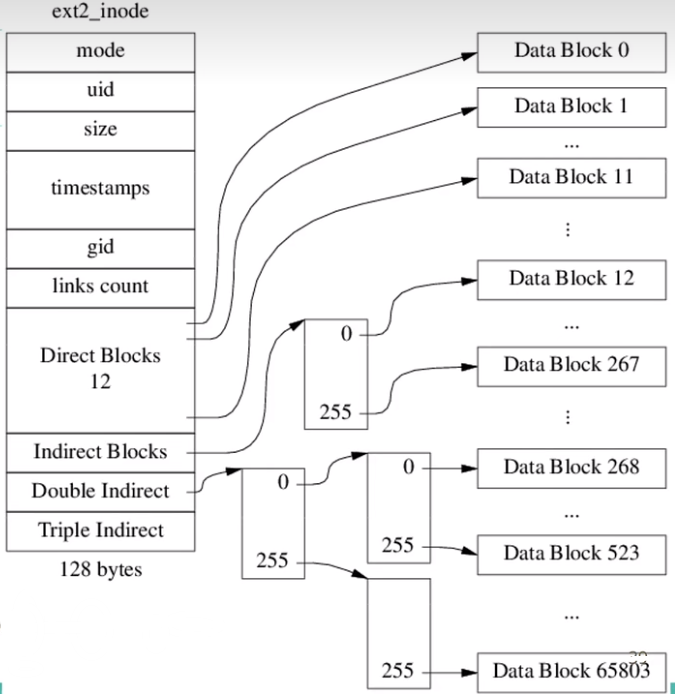
- inode的大小是128,因此1KB的block中有8个inode;
- 通过直接+三重间接的方式最多可以存$12+256+256^{2}+256^{3}=16843020$个文件block,也就是说文件最大的大小考虑到1KB block大约是16.063GB;
- 因此ext2比较适合小文件,大文件需要额外的开销;
- 该实现中,文件易于在尾部插入(O(1));在文件中间插入一个字节比较困难(类似于数组插入);
- ext4中不使用indirect blocks而是使用extent tree代替;另外使用extent(映射到连续范围的物理block)代替了direct blocks,一个extent最多可以在4KB block中映射128MB的空间;一个inode有四个extents;超过512MB的内容使用tree进行index;
Ext2与Ext4对比:

使用
df -i可能看到inode的使用;小文件占用inode比较多; 大文件占用storage比较多最大文件大小:
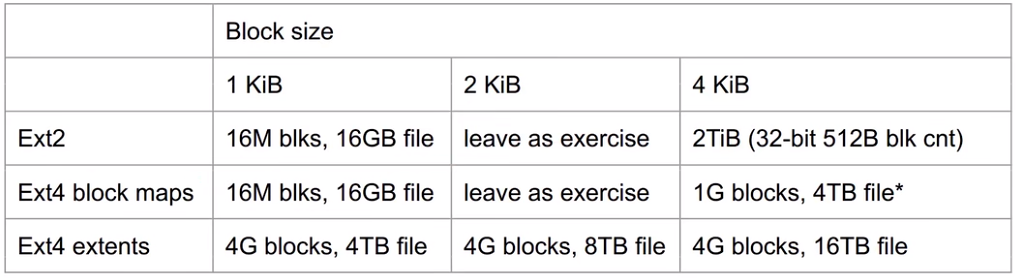
Ext4中一个文件系统能用拥有$2^{48}$的物理block,一个文件能拥有$2^{32}$的逻辑block;
从Linux系统的角度而言,inode=file;或者说inode相当于基类,它的子类有(regular file.directory,symbolic link,character device,block device,FIFO,socket);
inode里面一定包含:file size,refcount,block addresses,mode,timestamps;
一定不包含:file name,file offset;
文件系统抽象(简化):
1
2
3
4
5
6
7
8
9
10
11
12class FileSystem{
public:
using inode_num_t = uint32_t;
explicit Filesystem(BlockDevice* dev);
inode_num_t lookup(string_view path);
shared_ptr<Inode> getInode(inode_num_t);
private:
BlockDevice* dev_;
SuperBlock ssb_;
Map<string, inode_num_t> dirs_;
Array<Inode> sinodes_;
};inode抽象(简化):
1
2
3
4
5
6
7
8
9
10
11
12
13struct Inode
{
using block_num_t = uint64_t;
bool isDir( ) const;//提示文件类型
bool isFile() const;
bool isSymLink( ) const;
int64_t file_size;
int ref_count;
block_num_t getBlockNum(uint32 idx);
bool appendBlock(block_num_t blk);
private:
vector<block_num_t> blocks; // two ways
};
目录
unix 层次文件系统的五大亮点:
- 层次化文件系统,可以支持目录和子目录
- 万物皆文件(文件,设备等使用相同的接口)
- 能够起进程的能力(fork)
- shell
- 很多子功能 比如make等;
目录过去以链表的形式实现:

如图所示.是本目录,..是父目录,然后用链表连接entry,里面包含了文件名和inode(i1就表示inode);
可以理解为:
1
2
3struct Directory{
list<pair<inode_num_t,string>> entries;
};在ext2中,目录项可以理解为如下结构:
1
2
3
4
5
6
7struct ext2_dir_entry_2{
_le32 inode;// Inode number
_le16 rec_len;// Directory entry length_u8
name_len;// Name length
_u8 file_type;// New in v2
char name[];// File name, up to 255
};下面的命令造成的效果如图:
1
2
3mkdir test
touch hello
mv hello muduo
mv操作会在后面空闲的pad中创建muduo,然后把hello那部分释放;
移动指针的方式:
1
de=(ext2_dirent *) ((char *) de + rec_len);//相当于next
ext2使用16bit来指示目录中的引用数,这给文件数量带来了限制;另外因为使用链表实现目录,也给数量带来了限制;一个目录下大概可以有10-15k个文件;
另外目录是不会收缩的,可见的里面会有很多碎片;因此rsync(1)会在复制文件前创建好所有的目录,从而减少大目录的碎片
打开文件(open (“./chen/shuo/hello.txt”))的ext2的调用树(ftrace生成):

Ext4目录:
使用哈希表代替了链表;
1
2
3struct Directory{
HashMap<string,inode_num_t> entries;
};目录API:
fcntl.h: open(2);unistd.h:read(2)/write(2)/close(2)<sys/stat.h>:fstat(2)可以对目录open(2)或者fstat(2);但是read(2)会返回EISDIR;因为目录的格式是和文件系统相关的,不同的格式不一样;
要读的话使用用户态的:
<dirent.h>:opendir(3)/fdopendir(3)/readdir(3)/closedir(3);这部分会调用getdents64(2);从而获得给用户看的目录信息,格式如下:
1
2
3
4
5
6
7struct dirent {
ino_t d_ino;// Inode number
off_t d_off;// Not an offset;
uint16_t d_reclen;// Length of this record
uint8_t d_type; // Type of file;
char d_name[256];// Null-terminated filename
};其他的api:scandir(3),rewinddir(3),telldir(3);
磁盘布局
Ext2 中 block group每一个为8M或者128M(取决于block大小);每一个block group中的内容如下:
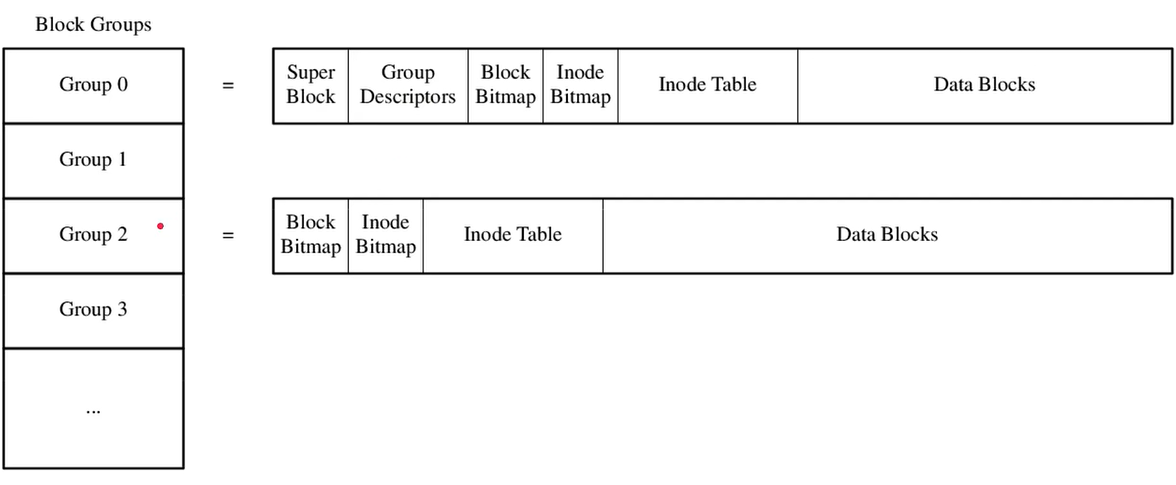
其中,group 0和group 1是一样的,从而备份super group; group 2里面的布局就是一般的存放数据的block的布局;
block bitmap与block的数量相关,因为其中的一个bit对应一个block;
group 0中的group descripter的结构如下:
1
2
3
4
5
6
7
8
9
10//Structure of a blocks group descriptor
struct ext2_group_desc ll sizeof(*this) == 32{
u32 bg_block_bitmap; // Blocks bitmap block
u32 bg_inode_bitmap;//Inodes bitmap block
u32 bg_inode_table;//Inodes table block
u16 bg_free_blocks_count;// Free blocks count
u16 bg_free_inodes_count;// Free inodes count
u16 bg_used_dirs_count;// Directories count
};
//处于group 0 中;创建500M文件系统rev.1 image的命令案例:
1
2
3
4dd if=/dev /zero of=m580M bs=1M count=500
mkfs.ext2 m580M
查看信息:
dumpe2fs m500M创建一个文件系统并且mount的案例:
1
2
3
4
5dd if=/dev/zero of=ext2.img bs=1M count=500
mkfs.ext2 -r 0ext2.img
sudo mount ext2.img /mnt / smal
copy files to it, then umount
debugfs -w ext2.img1000MB,4KB block,256000 blocks,32768 blocks per group,8 groups;256B inode,16 nodes per block,8000 inodes per group,500 inode blocks per group案例:
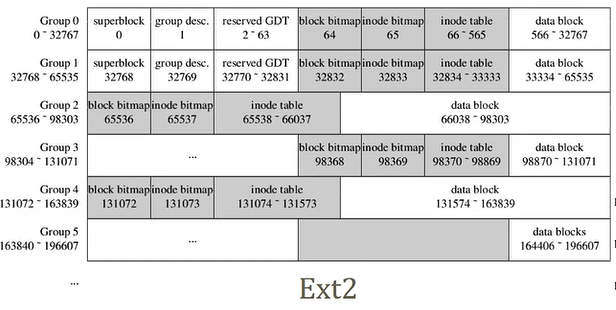
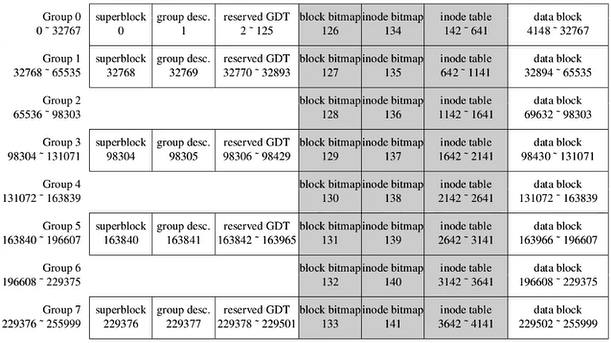
Ext4上述配置的案例:
super block:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19/*
*Structure of the super block
*/
struct ext2_super_block {
__u32s_inodes_count;/*Inodes count*/
__u32s_blocks_count;/*Blocks count */
__u32 s_r_blocks_count;/* Reserved blocks count */
//下面这两个会很容易产生竞争,因为与文件创建有关系;
__u32 s_free_blocks_count;/*Free blocks count */
__u32 s_free_inodes_count;/* Free inodes count*/
__u32s_first_data_block;/* First Data Block */
__u32 s_log_block_size;/*Block size */
__s32 s_log_frag_size;/*Fragment size */
__u32 s_blocks_per_group; /*#Blocks per group */
__u32 s_frags_per_group;/*# Fragments per group*/
__u32 s_inodes_per_group;/*#Inodes per group */
//...
}Magic Numbers:
Ext2/Ext3/Ext4: 0xEF53
UFS1/UFS2: 0x19540119 (Marshall Kirk McKusick的生日)
根据inode以及super block的参数就可以定位inode的位置:
1
2
3
4
5
6
7
8
9ino > 0,0 is invalid value.
group = (ino-1) / inodes_per_group //得到group
offset_in_group = (ino-1) % inodes_per_group //inode是group中的第几个
block = group_descs[group].bg_inode_table + offset_in_group / inodes_per_block //其实就是起始偏移量加数量;
offset_in_block = offset_in_group % inodes_per_block //block的第几号
struct ext2_inode inodes[inodes_per_block];//inode缓冲区
dev->readBlock(block, inodes); //把对应的block读到结构体数组中
return inodes[offset_in_block];//得到inode;案例:

Ext2和Ext4对比:
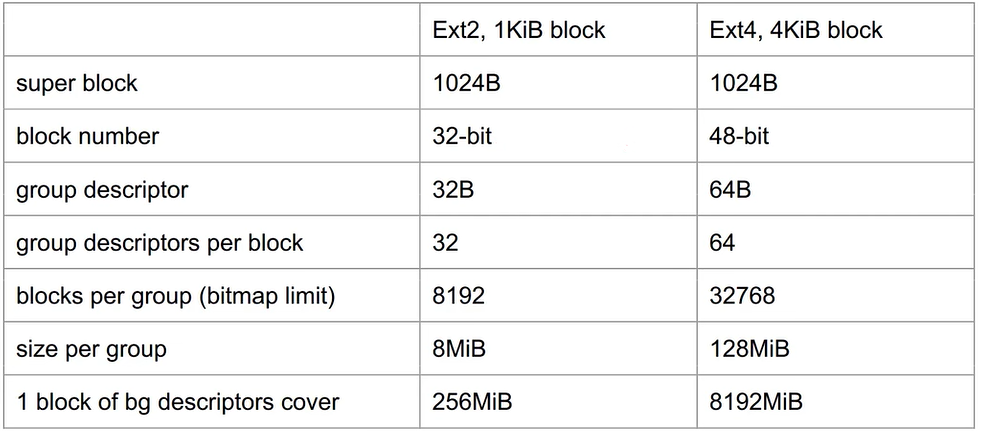
Ext2/Ext4中inode的最大数量是$2^{32}$,因为inode number是32-bit;
文件的数量一般在创建文件系统的时候固定为:block size/ inode size;
文件名的长度:255;
每一个inode的链接的数量:
i_links_count是16-bit,对于Ext2为32000,对于Ext4为65000,这限制了每一个目录里面的子目录数量;Ext2中因为是线性搜索所以对目录里面的条目有限制,否则会效率大大降低;Ext4支持一个目录中有上百万个文件;
补充:Linux文件权限
在Linux操作系统中,每个文件和目录都有三种不同的权限:读取权限、写入权限和执行权限。这些权限是用来控制不同用户对文件和目录的访问权限的。
具体来说,每个文件和目录都有一个所有者(owner)和一组用户组(group),还有其他用户(others)。每个用户可以被分配到这些角色之一,以确定他们对文件和目录的访问权限。
这些权限用数字或者字母表示,分别是4(r)、2(w)、1(x)。数字4表示读取权限,数字2表示写入权限,数字1表示执行权限。这些数字可以组合在一起来表示所有者、用户组和其他用户的权限。例如,数字755(rwxr-xr-x)表示所有者(4+2+1=7)有读取、写入和执行权限,用户组(4+1)和其他用户(4+1)只有读取和执行权限。
数字与字母符号的对应关系表格如下:
| 数字 | 字母符号 | 权限 |
|---|---|---|
| 0 | — | 没有任何权限 |
| 1 | –x | 执行权限 |
| 2 | -w- | 写入权限 |
| 3 | -wx | 写入和执行权限 |
| 4 | r– | 读取权限 |
| 5 | r-x | 读取和执行权限 |
| 6 | rw- | 读取和写入权限 |
| 7 | rwx | 读取、写入和执行权限 |
使用ls-l的时候可以显示文件和目录的权限,第一个字符表示文件类型(d表示目录,-表示常规文件),后面的9个字符表示文件的权限,其中前三个字符表示所有者的权限,中间三个字符表示用户组的权限,最后三个字符表示其他用户的权限。例如:
1 | -rw-r--r-- 1 user user 4096 Apr 30 23:00 example.txt |
补充:Linux权限管理
linux操作系统有严格linux操作系统有着严格、灵活的权限访问控制。主要体现在两方面:
1、文件权限
2、进程权限
文件权限:文件除了r,w,x之外还有s,t,i,a权限。具体可以参考博文
进程是用户访问计算机资源的代理,用户执行的操作其实是带有用户身份信息的进程执行的操作。进程id有以下三种:
- RUID - 真实用户ID,标识运行程序的用户
- EUID - 有效ID,告诉内核进程的特权
- SUID - 当进程更改其UID时使用的保存用户ID
可以使用如下命令查看进程的用户id:1
2
3ps -C test_id -o pid,tty,ruser,user,cmd
PID TT RUSER USER CMD
3250 pts/1 joe root ./test_id
在文件权限和进程权限id里,s文件权限和euid权限id是sudo实现提升权限的根本。一个进程是否能操作某个文件,取决于进程的euid是否拥有这个文件的相应权限,而不是ruid。也就是说,如果想要让进程获得某个用户的权限,只要把进程的euid设置为该用户id就可以了。在具体一点,我们想要让进程拥有root用户的权限,我只要想办法把进程的euid设置成root的id:0就可以了。
Linux提供了一个seteuid的函数,可以更改进程的euid。函数声明在头文件里。1
int seteuid(uid_t euid);
但是,如果一个进程本身没有root权限,也就是说euid不是0,是无法通过调用seteuid将进程的权限提升的,调用seteuid会出现错误。 那该怎么把进程的euid该为root的id:0呢?那就是通过s权限。
如果一个文件拥有x权限,表示这个文件可以被执行。shell执行命令或程序的时候,先fork一个进程,再通过exec函数族执行这个命令或程序,这样的话,执行这个文件的进程的ruid和euid就是当前登入shell的用户id。
当这个文件拥有x权限和s权限时,在shell进行fork后调动exec函数族执行这个文件的时候,这个进程的euid将被系统更改为这个文件的拥有者id。
比如,一个文件的拥有者为user_1,权限为rwsr-xr-x,那么你用user_2的文件执行他的时候,执行这个文件的进程的ruid为user_2的id,euid为user_1的id。
创建一个main.c文件,并写入如下代码:1
2
3
4
5
6
7
8
9
10
#include <stdio.h>
#include <unistd.h>
int main(int argc, char* argv[])
{
printf("ruid: %d\n",getuid());
printf("euid: %d\n",geteuid());
return 0;
}
编译代码1
gcc ./main.c -o ./main
编译运行,结果如下:1
2ruid: 1000
euid: 1000
通过chmod和chown为文件更改拥有者和添加s权限1
2sudo chown root ./main
sudo chmod +s ./main
再次运行,结果如下:1
2ruid: 1000
euid: 0
此时由于文件的s权限,euid已经变为了root的id:0
将代码修改如下:1
2
3
4
5
6
7
8
9
10
11
12
13#include <stdio.h>
#include <unistd.h>
int maind(int argc, char* argv[])
{
printf("ruid: %d\n",getuid());
printf("euid: %d\n",geteuid());
if(execvp(argv[1], argv+1) == -1){
perror("execvp error");
};
return 0;
}
编译1
gcc ./main.c --o main
执行如下命令1
2
3sudo chown root ./main
sudo chmod +s ./main
./main apt update
可以看到,已经成功运行apt并进行了软件列表的更新。
查看sudo的权限1
ls -al /usr/bin/sudo
输出如下1
-rwsr-xr-x 1 root root
可以看到,sudo就是一个拥有者为root且拥有s权限的可执行文件。
当然sudo的实现要比这复杂的很多,比如sudo通过检查配置文件,来决定哪些用户可以使用sudo,为了安全考虑sudo还要求验证ruid的用户密码等。
总结:如果文件拥有s权限,那么可以让使用者拥有创建该文件的用户的权限;sudo的原理之一就是root用户是sudo的创建者并且sudo程序文件拥有s权限。
