核心概念
Infiniband的优势:
- 支持大量协议:包括通过IB光纤的非IB协议的隧道包,例如IPv6、Ethertype包;
- 高带宽,吞吐量可实现2.5Gb/s,10Gb/s,30Gb/s;
- 低延时,应用程序时延 <3us;
- 高可扩展性的拓扑结构;
- 非特权应用发送接收信息时,内核不用进行特权模式的切换;
- 每个信息都由CA(通道适配器)的硬件DMA直接传输,而不用处理器的参与,也就是RDMA;
- 大部分协议都可以在芯片上实现,减少软件和处理器的负荷。
一些专业术语:
- 处理器节点(processor Node):一组或多组处理器以及其内存,并通过主机通道适配器(HCA)与IBA光纤连接,每个HCA都有一个或多个端口;
- 端口(port):IBA设备与IBA链路连接的双向接口;
- 链路(link):用于两台IBA设备的两个端口间的双向高速连接。具体应用中以serdes实现,单条链路的传输速率可达2.5Gb/s,250MB/s的吞吐率(由于serdes中8b/10b的原因)。此外,还可以用4条或12条链路,达到1GB/s和3GB/s的吞吐率;
- 通道适配器Channel Adapter(CA):每个CA port在配置时就具有唯一地址,当一个CA必须发送信息或者读取信息时,首先需要发送一个请求报文,该报文带有destination port ID,通过交换机和路由器的帮助,CA最终抵达目标CA。
- IO单元与IO控制器(IOU and IOC):IOU的组成包括,连接到IBA的目标通道适配器;一个或多个IO控制器提供的IO接口,其实现形式会是一个大量的存储矩阵;
子网:一些有相同子网ID和相同的子网管理器的端口和链路的集合。
- 子网管理器(SM)会在子网启动时发现所有设备,配置它们,并在后续周期性检查子网的拓扑结构是否被修改;
- 在配置过程中,子网管理器会为每个端口配置一个独有的本地ID和一个相同的子网ID,用以标识子网和端口位置;
- 能交换数据包的所有的CA、路由器端口以及交换机端口都可以被叫做在同一个子网下;
- 子网间可以通过路由器进行相互连接。
报文:详细见之前的博客;报文是用来在两个CA之间发送请求(request)或者响应(response)信号,一个报文的有效荷载(payload)部分最大可以包含4KB数据。CA如果需要发送的报文大于此长度,需要对此进行切分,分为多个包传输。每个报文分为payload、路由报文头(header)、CRC校验等;header包括本地路由头部(LRH),全局路由头部(GRH),基础传输头部(BTH)
系统案例:
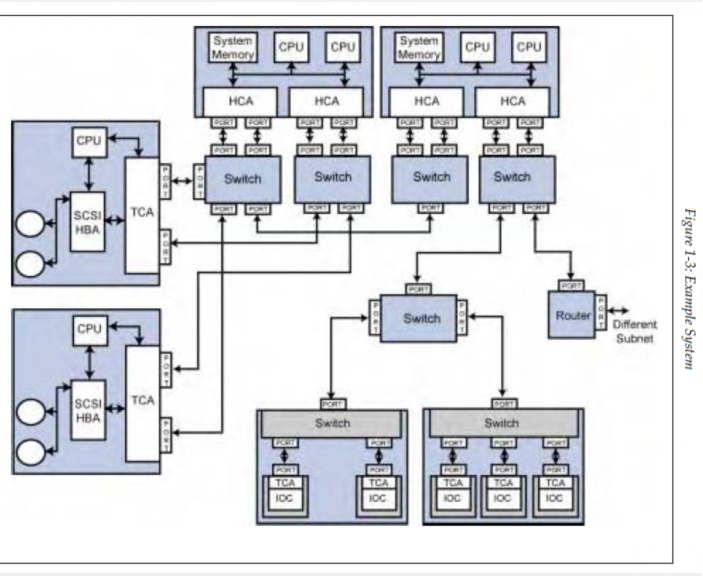
当一个请求报文由CA发送后,会有以下两种情况:
- 源CA和目标CA直接连接:这种情况下,报文通过唯一链路,对头部中的DLID信息解码后直接找到目标CA port,目标CA接受请求后,并作出对应处理;
- 源CA和目标CA非直接连接:请求报文不能直接抵达目标CA,所以其需要先前往交换机或者路由器的port。
交换机和路由器规则:
- 交换机规则:负责在同一子网内报文的路由,根据DLID查找交换机内部的转发表(由软件在启动阶段配置),确定报文需要从交换机的哪个端口输出。(一个报文在抵挡目标CA前可能需要经过多个交换机)
- 路由器规则:当源CA和目标CA不在同一子网下,请求报文会带有GRH。交换机会在子网下不断路由报文,直到抵挡路由器的一个port,然后路由器根据GRH:DGID确定目标CA在哪个子网下,与交换机类似,路由器内部存在路由表。(一个报文在抵挡目标CA前可能需要经过多个交换机)
报文传输类型
IB协议中的消息传递是建立在CA间的,其本质是CA间的内存空间进行数据交换。
三类消息传输:
- 从本地CA的内存传输信息到目标CA的内存;
- 信息发送操作:请求信息不会通知CA数据该写到哪块内存中,而是对端CA自行决定数据的存放地址;
- RDMA写操作:请求报文会指定数据需要写到对端CA的哪块内存中,报文包括了有效荷载,请求报文的内存起始地址、报文长度和允许该RDMA写操作的一个密钥。
- 从目标CA的内存读取信息,并存储在本地CA的内存中;
- CA向对端CA发出读指定内存中数据的请求,对端CA接收该请求后,会返回一个或多个响应报文,请求端将返回报文中的数据存储到指定内存中。
- 对目标CA的内存执行原子操作(读/改/写),并将返回的数据存储在本地CA的内存。
- 原子读取和加法操作:收到请求后,目标CA从其本地的指定内存中读取数据,将Add值与读取数据相加,并将结果写回本地内存。目标CA将读回的初始值以原子响应包的形式返回给请求端CA。收到响应数据包后,请求端CA将读数据写入自己的本地内存;
- 原子比较和交换操作:收到请求后,目标CA从其本地的指定内存中读取数据,将读取的数据与Compare值比较,若相等,将值写入指定位置,返回的响应操作与上述加法原子操作一致。
- 从本地CA的内存传输信息到目标CA的内存;
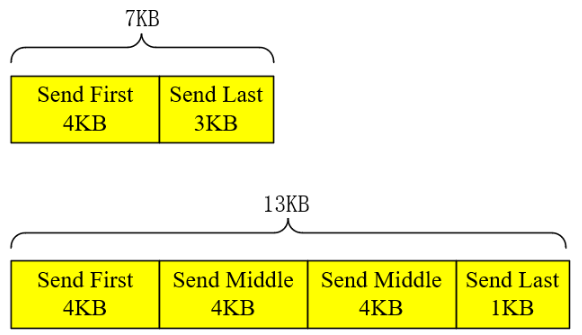
Single packet & Multiple packet:
- IBA标准中最大包的长度限制为4KB,大约4KB的信息并非不能传输,而是需要拆分为多包传输(multiple packet)。
- 如果信息总长在4KB~8KB,multiple packet将分为Send First操作与Send Last操作;
- 如果信息总长大于8KB,将分为Send First、Send Middle和Send Last操作,其中,非第一包和最后一包的数据都为Send Middle操作。
# 属性与管理器
略
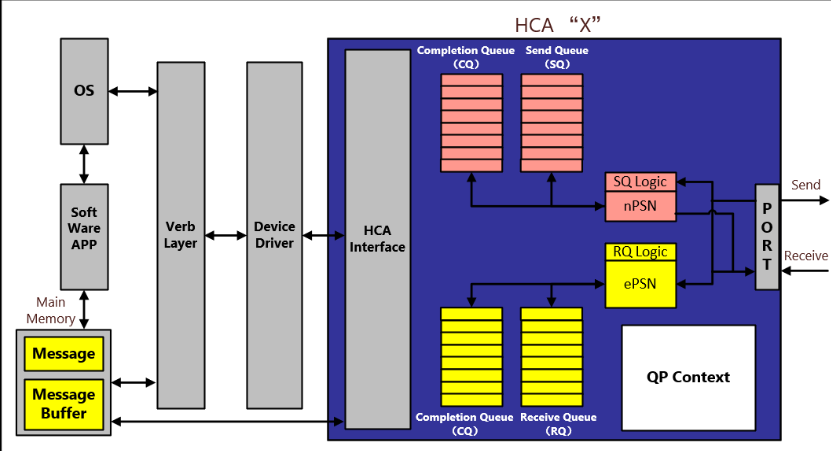
QP:消息传递机制
QP是一个双向的消息传输引擎
每一个CA实现数量多达$2^{24}$对QP;QP包含两个队列:
- 发送队列:软件将消息传输请求(WQE)发送到SQ,执行时,SQ将出站消息传输请求发送到对端QP的RQ;
- 接收队列:软件将工作请求(WQE)发送到此队列,以处理通过对端QP的SQ传输到RQ的不同类型的入站消息传输请求。
QP的SQ会以一系列的,一个或多个请求包的形式向远端QP的RQ传输消息传输请求;
根据QP类型,远端QP的RQ可以通过向对应的SQ发送一系列的,一个或多个响应数据包来响应接收到的消息传输请求。
报文序列号PSN:
SQ生成的每个请求包都包含一个PSN,收到请求数据包后,RQ将验证数据包是否与期望的PSN (ePSN)一致。
与之对应的,RQ生成的每个响应包都包含一个PSN,该PSN将它与从远端SQ接收到的请求包关联,SQ收到每个响应包时, 将验证包的PSN是否与之前发出的请求相关联。
QP服务类型
- 可靠连接 RC(Reliable Connected)QP;
- 非可靠连接 UC(UnReliable Connected)QP;
- 可靠数据报 RD (Reliable Datagram) QP;
- 非可靠数据报 UD (Unreliable Datagram) QP;
- 类似与隧道包,对非IBA协议的包进行封装的 RAW QP。
QP类型
RC QP特性
- 建立QP
- 初始化本地CA的端口号用于发送接收信息;
- 初始化QPN,用来指示远端CA的RC QP
- 初始化远程 RC QP 所在的远程 CA 端口的端口地址
- 私有的传输信道:
- RC QP只会和对端的RC QP接受和发送信息
- Ack/Nak协议:
- 如果成功接受并且执行了Send和Write请求的话会返回Ack包
- 以下情况会返回Nak:
- RNR Nak(Receiver Not Ready);这种情况发送方的QP可能会持续的重复发送请求包直到悲成功执行或者达到发送方的重传计数
- PSN Sequence Error Nak;这种情况意味着一个或者多个包丢失了;这里会倒回并且重传直到远端接收到了或者重传次数耗尽;
- Fatal Nak error code;如果远端QP的RQ逻辑在请求包或者试图执行的时候触发了错误;这种情况不会尝试重传,错误会被报告给发送端软件;
- RDMA Read Reponse packet:这是RDMA Read请求的回复;一般以一系列,一个或者多个RDMA Read Response包进行返回;
- Atomic Response packet:这是原子请求的回复,请求的数据会以一个单独的Atomic response 包返回;
- reliable的原因:
- 远端QP的RQ逻辑会对于每一个请求包确认PSN来保证信息的请求报文都是按照顺序接受的,并且没有遗漏;如果请求报文接受超过一次那么只会执行一次(有一个例外:在接收到重复的内存读的请求之后数据会再次从内存读取);
- 发送端QP的SQ逻辑会对于每一个请求报文检查应有的回复;如果接收到RNR Nak或者PSN Sequence Error Nak,SQ逻辑无需软件就能自动尝试恢复;
- 带宽利用:由于会产生Ack和Nak,该协议会占用大量的IBA带宽;
- 信息长度:每一个信息包含0-2GB的数据
UC QP 特性
- 建立QP:
- 初始化本地CA的端口号用于发送接收信息;
- 初始化QPN,用来指示远端CA的UC QP
- 初始化远程UC QP 所在的远程 CA 端口的端口地址
- 私有的传输信道:
- UC QP只会和对端的UC QP接受和发送信息
- 无Ack/Nak协议:对于所有的请求不保证被对端QP RQ逻辑正确接受;
- 带宽利用:因为不产生Ack、Nak所以UC协议相对于RC协议显著减少了带宽消耗;
- 消息长度:每一个信息包含0-2GB的数据
RD( Reliable Datagram) QP 特性
- 通用的(传输信道):
- RD QP能够和任意数量的RD QPs发送和接受数据;实现的原理是它在本地CA和一个或者更多的远端CA之间建立一个或者更多的“通道”;”通道“称作Reliable Datagram Channel (RDC);
- QP发送的请求包中包含对于本地CA中的RDC的信息转发请求;RDC经过编程会发送和接受通过一个特定本地CA端口的所有包;The RDC is also programmed with the address of a port on the remote CA behind which the other end of the RDC resides, as well as the address of the otherend of that RDC.
- 多目的地的传输信道:
- RD QP可以对于其他CA的多个RD QPs发送和接受信息
- Ack/Nak协议:和RC的这部分一样
- 带宽利用:由于会产生Ack和Nak,该协议会占用大量的IBA带宽;
- 消息长度:每一个信息包含0-2GB的数据
UD QP 特性
- 通用:
- UD QP能够与任意数量的其他UD QPs发送和接受数据,并且每一个请求报文接收到之后不需要Ack或者Nak
- 对于本地CA端口的QP Bound:软件初始化之后,UD QP会在本地CA上面初始化,并且附有一个用于接受和发送信息的端口号;在这之后,它只能通过该端口和远端UD QPs发送和接受信息
- 多目的地的传输信道:
- UD QP可以对于其他CA的多个UD QPs发送和接受信息
- 无Ack/Nak协议
- 带宽利用:因为不产生Ack、Nak所以UD协议相对于RC,RD协议显著减少了带宽消耗;
- 消息长度:传输的消息的长度不能超过单个数据包的载荷;
Raw QP
- Raw QP用于与不是IBA协议的例如IPv6或者以太网协议发送和接受信息;交换机与路由器需要保证能把他们传到最终目的地
QP的SQ和RQ逻辑
QP的SQ逻辑
- 处理软件传入的work requests;一旦一个WR被传给SQ,它就会被认为是WQE,work queue entry;这些WQE会被QP的SQ逻辑一次一个的按照他们传入的顺序进行处理;
- 处理WR的传输,也就是如果请求数据包发送方期望ACK那么SQ的逻辑会等待Ack报文,当接收到的时候检验顺序的正确性以及他们没有错误
- 处理带内的RDMA读响应报文的数据;这些数据根据SQ WQE里面的指针写入到CA本地内存中
- 处理带内的原子请求返回的数据项;同样这些数据会根据SQ WQE里面的指针写入到CA本地内存中
QP的RQ逻辑
- 当接收到请求包的时候检验PSN是期望的PSN(expected PSN,ePSN);
- 当接收到请求包的时候,如果请求包的接收者期望ACK,那么RQ逻辑会发送ACK报文给远端的QP的SQ逻辑;Ack的PSN和被确认的那个请求包的PSN相同
- 如果请求包是Send,那么请求报文的数据负载会使用当前位于RQ顶部的WQE指定的Scatter Buffer List写入CA的本地内存;在收到Send的最后一个或者唯一的数据包之后,RQ逻辑会从RQ中停用顶部条目;此外它会将一个完成队列条目CQE发布到与QP的RQ关联的CQ里卖弄;如果可选的32位及时数据值存在于最后一个或者仅有的Send请求包中,那么RQ逻辑会把及时数据值存储于新发布的CQE中;
- 如果请求包是Write;那么请求的数据包负载会更具RDMA写请求的第一个请求报文中提供的指针写入到CA的本地内存中;
- 如果请求包是最后一个或者唯一的Write并且该数据包含有可选的32位及时(immediate)数据值,RQ可以会停用顶端的条目,另外会发布一个CQE到关联与QP的RQ的CQ中并且在这个CQE中存储刚刚的及时数据值;
- 如果请求是一个Read,那么QP的RQ逻辑会根据RDMA Read请求报文中提供的起始内存地址来读取数据;折后这些数据会通过一系列一个或者多个RDMA Read响应报文发回远端QP的SQ中;
- 如果请求是一个原子操作,那么RQ逻辑会根据报文中指定的地址在本地内存中执行操作,并且把在该位置读取的数据返回给远端QP的SQ逻辑;
Verb layer 是操作系统-独立的API
我认为这里的Verb layer指的就是Send,Receive,Write,Read等动词;
对于每个verb,规范定义了:
- 输入的参数
- 返回结果,输出的参数
- verb的操作类型
这里verb layer能够触及HCA 硬件接口(例如寄存器组)来通过HCA达成想要的动作;另外,Verb layer还能够:
- 在需要的时候调用操作系统;例如它可以调用OS的内存管理器,为verb或者HCA的使用分配物理内存;
- 必须通过verb调用请求的操作,才能访问主存。例如,在特定的操作系统环境中,软件应用可以在主存中构建一个消息传输工作请求(WR),然后执行Post Send Request verb调用,将WR发布到QP的SQ中进行处理。它将在主存中提供WR的起始地址作为Post Send Request verb的输入参数之一,然后verb将访问主存以读取WR,将WR发送到目标QP的SQ。
QP Context中定义了QP的可选特征
在使用QP进行发送或接收信息前,软件会先创建一个QP,并提供一些其在发送、接收过程中需要用到的特征。
以RC类型的QP为例,QP Context大致会包含以下内容:
- 本地端口号(在QP创建时确定);
- QP类型;(包括RC,UC,RD,UD,Raw)
- SQ开始PSN(SQ发送的第一包插入开始PSN,后续实时更新current PSN);
- RQ期望PSN(RC协议里面会检查到来的包的PSN是不是下一个期望的PSN,如果不是会返回PSN Sequence Error Nak;如果正确则返回Ack);
- 最大payload尺寸(0.25KB、0.5KB、1KB、2KB、4KB,也被称作path maximum transfer unit,PMTU;这里PMTU相当于从起点到目的地经过的路径中的MTU最小值);
- 目标端的本地ID;(指的是远端QP所在的CA的端口的destination local ID address)
- 期望的本地QoS;(可以通过指定所需要的服务级别(SL)来指示所需要的QoS,这是一个4-bit的值用于决定从源端口发送的速度;另外交换机也会查看SL值来确定数据包以多快的速度转发)
- 报文注入延迟(IPD;因为链路的宽度不同,内部报文延迟也不同,防止快速链路的流量超过较慢链路的流量,QP会附一个IPD来定义将数据包发送到目标IP之间必须遵守的间隔);
- 本地应答超时(指定时间内没收到ack报文,即为应答超时,需要重发对应报文);
- Ack timeout/丢包重传计数;
- RNR重传计数;(值由远端QP在两个QP第一次建立的时候提供,定义了SQ在接收到远端QP的RNR Nak之后重传的次数;远端QP在临时没法处理请求的时候会发送RNR Nak;典型的例子是接收到了请求数据包但是没有WOE发布到接收方的RQ中来处理这个请求)
- 源端口本地ID;(设置软件会给端口分配基本LID地址以及能够从该地址开始的LIDs数量;QP的SQ逻辑发送请求数据包给它分配的端口来传输的时候需要给端口指示要在数据包的SLID字段插入的LID地址,指示的方法是通过给出相对于基本LID地址的偏移;当QP设置的时候,它会被编程到RC,UC或者UD QP的QP上下文里面,称为Source Path Bits)
- 全局的源端/目标端地址;(如果目标CA和源CA不在一个子网,那么数据包就必须包含Global Router Header(GRH),因为数据包需要经过一个甚至更多的路由来到达目标CA;GRH包含了源端口的128-bit的Source Global ID(SGID)以及目标CA端口的128-bit的Destination Global ID(DGID))
- DGID:当QP设置的时候,软件需要提供远端QP所在的目标CA的DGID;然后这个DGID地址会插入到之后的每一个该QP的SQ逻辑产生的请求数据包里面
- SGID:
- 首先,每一个端口至少有一个设备制造商分配给它的64位GUID地址,该GUID地址存在于端口的GUIDInfo属性的条目0里面;SM可以使用条目1到n来给这个端口分配额外的GUID;
- 然后SGID的前64位是由端口的64位子网ID(GIDPrefix属性)提供的;设置RC,UC或者UD QP的时候,软件将指示哪一个本地端口的GUIDs会插入到QP生成的每一个数据包的SLID字段里面;此信息以端口的GUIDinfo属性提供给QP上下文;
- 额外的全局地址信息:
- Traffic Class(TClass): 此值指示请求数据包跨多个子网到达目标 CA 端口想要的 Qos
- Flow Label: 如果非0的话,那么要求路径上的所有路由器保证具有相同流标签值的所有数据包按照正确的顺序传递给目标CA端口
- Hop Limit: 路径上每一个路由器都会降低Hop Limit。如果耗尽就会丢掉这个包;
QP传输实例
实例场景
- 都是RC服务类型的QP;
- SQ PSN起始地址在CA X为100,CA Y为2000;
- 两个QP刚刚创建并且还没有发送任何包
- RQ 期望PSN CA X为2000,CA Y为100;
- 需要发送的信息为5KB,报文payload最大尺寸限制为2KB;
- Ack重传计数为7,RNR重传计数为7;
- Source CA与destination CA在同一子网下;
1. Posting the Message Receive Request
在CA X 的QP的SQ逻辑会在本地内存读一个5KB的信息然后发送给目标的QP的RQ逻辑;在接收到信息之后,RQ逻辑会用当前发布到RQ的顶端的WQE来确定在它本地内存的哪一个位置写接收到的数据;因此第一步是CA Y预先往本地QP的RQ里面发一个WR,以下是软件执行的步骤:
- 通过场外手段协商得知到来的包大小或者先不决定包大小,第一个包来了返回RNR Nak,然后往CA的寄存器设置标志位来指示发布一个WR来处理预期的重传;然后对应的软件就会触发中断,检查状态,往指示的QP的RQ发布报文来处理重传;
- 场景假设是在接受第一个请求报文之前发布WR,这里在CA Y的软件通过执行 Post Receive Request verb 来发布WR,传入的WR有以下输入参数:
- QP handle用来指示往哪一个QP发布;(这个由调用Create QP 返回)
- 一个特定的64-bit WR ID;该WR ID将存放在CQE里面;CQE会在所有的信息写入到CA T的本地内存之后再RQ的CQ里创建;
- 操作类型:Receive
- Scatter Buffer List,用于指示写带内数据的位置;
- 在接受到WR之后,Post Receive Request verb 会让WR发布到QP的RQ的下一个条目上;此时WR可以称为WQE(Work Queue Entry)
2. Posting the Message Send Request
软件通过如下步骤让QP的SQ传信息到另一个CA的QP的RQ中:
- 首先在本地内存里创建信息;
- 通过调用 Post Send Request verb ,并传入具有以下参数的WR:
- Create QP 返回的 QP handle
- 一个特定的64-bit WR ID
- 操作类型:Send
- Gather Buffer List来指明要发送的5KB信息的本地内存地址
- 可选的32位临时数据值;在接收到5KB 信息之后,远端CA的QP的RQ逻辑会把这个值存在它在QP关联的CQ里面创建的CQE中;该值可以用来提醒响应的软件有关其收到的信息的性质;
- 接收到WR之后, Post Send Request verb会让WR发布到QP的SQ的下一个条目上;此时WR可以称为WQE。
### 3. 发送第一个请求报文
- SQ开始处理顶层条目,WQE指定一个多个包的Send操作,将5KB消息从HCA本地内存发送到对端CA的QP;
- SQ检查QP Context中的PMTU来决定请求报文的最大数据大小,在本例中,SQ会选择前2KB数据作为第一个请求报文发送;
- SQ在第一包的Opcode内容中填入Send first,向对端RQ表示,该包是第一发送包,(对端在接收到Send last包之前是不知道Send操作的长度的)
- SQ往PSN字段填入发送逻辑的cPSN(当前PSN),因为是起始,以及上述案例条件所以是100;
- SQ根据QP context内容设置DestQP字段;
- SQ将请求包转发到端口X进行传输时,向端口提供基本LID地址的偏移量,以替代包的SLID;
- SQ将第一个请求包内的DLID设置为目标CA端口的QP的DLID,DLID来自QP Context;
- SQ根据QP context内容设置服务等级(Service Level);
- 如果请求操作中存在全局ID,SQ需要在第一包中插入GRH(但在本例中不需要);
- Send操作的第一个请求包被发送到网络层,然后转发到HCA端口(X)的链路层。此外,SQ还做以下工作:
- 将nPSN从100更新到101,这是将在发送的下一个请求包中插入的PSN。
- 等待收到“Send First”请求包的对应Ack包。
- 形成下一个请求包发送到链路层进行传输。
- 当从网络层接收到第一个报文后,端口的链路层将:
- 在端口的base LID上加入偏移,并将此LID插入在请求报文中的SLID中;
- 如果目标CA和源CA不在同一子网下,会生成一个128-bits的SGID;
- 在配置过程中,SM设置了端口的SLtoVLMappingTable属性表,将16个可能的SL值映射到特定的链路层传输缓冲区。SM还建立了一个仲裁方案,为每个传输缓冲区分配一个重要级别。定义了传输缓冲区以什么顺序将数据包传输到端口的物理层;
- 请求包被发布到链路层选择的传输缓冲上;
- 当该VL传输缓冲区进行报文传输时,端口的链路层将请求报文转发给端口的物理层进行传输。数据包的VL字段标识了各自的VL接收缓冲区,该缓冲区将在与该端口连接的物理链路的另一端接收数据包。
- 从X链路层端口流出的请求报文将根据serdes的规范,编码为10-bits的串行流;
- 请求包经过一个或多个链路,最后到达目标端口。每个交换机查找内部转发表,并根据包内的DLID确认向何处转发;
- 目标QP端口对从物理层收到的数据解串行化,恢复8-bits数据流,并传递给链路层;
- 链路层解析包内的DLID项,确定数据前往哪个端口;
- 链路层将数据传输到数据包指示的VL接收缓冲区;
- 请求包转发至网络层;
- 网络层根据DestQP项将数据传递到对应RQ;
- RQ将请求包的PSN与ePSN比较,确定是否出现丢包(如果PSN为之前请求包范围内的PSN,代表是一个重复包,不需要响应其动作,但要回复ack);
- RQ将检查包的opcode,确认是否需要WQE将报文写入CA Y的本地内存中。如果opcode是send或RDMA write with Immediate操作,那么需要RQ有一个WQE。如果RQ当前没有发布WQE,则需要返回对端SQ一个RNR NAK包;
- RQ逻辑检查opcode确保有效,比如这里应该是”Send first”而不是”Send Middle”或者其他;若有效则继续执行
- RQ返回一个Ack包给发送端的QP的SQ逻辑;SQ的处理在下一个部分”First Ack Packet Returned”;
- RQ逻辑使用在RQ顶部的WQE信息确定数据包的载荷应该写的内存的位置;
- 使用来自RQ WQE的Scatter Buffer List把请求报文的数据载荷写入本地内存
- RQ逻辑更新RQ WQE里面的指向剩余内存部分的内存指针(也就是下一个Send操作包应该写的位置);
- RQ逻辑更新自己的ePSN为ePSN+1(这里为ePSN=101s),并且等待下一个包
4. 第一个Ack报文返回
在接收到”Send First”报文之后,接收端RQ逻辑会往请求方发送一个Ack包,Ack包的PSN和”Send First”请求包的PSN一致;Ack的传输如下:
- 接收端的QP的RQ逻辑将ack包发送到网络层,然后转发至端口的链路层
- Ack报文不包含数据载荷层;而是包含了一个Acknowledge opcode和Acknowledge Extended Transport Header(AETH)层;opcode暗示这是一个ACK报文,AETH中包含了ACK报文的信息: positive Ack或者 Negative Ack(Nak),如果是Nak的话,会包含Nak的原因;
- Ack的DestQP中装载了QPN用于指定请求的QP
- 在本案例中AETH暗示了这是一个positive Ack
- Ack中使用的SL需要和请求报文里面的SL一致
- 请求包中的SLID和DLID在Ack包中是相反的(源–目的调换)
- 接收端端口的链路层借助Ack报文中的SL值,对于SLtoVLMappingTable进行查表来决定使用链路层的哪一个VL(Virtual Lane) transmit buffer来发送Ack报文
- Ack报文发送到指定的VL transmit buffer中
- 当VL transmit buffer轮到该Ack报文的时候,端口的链路层把Ack报文转发到物理层进行传输;Ack报文的VL字段显示了另一端的物理层(要么是交换机端口要么是对端CA的目标端口)应该接受这个Ack报文的VL receive buffer
- Ack报文的链路层的8-bit 字节流在物理层编码成了10-bit字符然后转换成序列比特流在线上传输
- Ack报文经过一或多条链路直到到达目标端口
- 目标端口的物理层对数据进行解序列,从10-bit字节解码成8-bit字节,并且转发给端口的链路层
- 链路层解码逻辑解码DLID字段确定自己就是目标端口
- 链路层接受Ack包字节流到VL receive buffer里面,这个buffer是由Ack报文的中的VL值指定的;
- Ack报文转发到网络层
- 网络层把Ack报文发给SQ逻辑;
- SQ逻辑通过AETH来确定是positive Ack还是Nak;本例中是前者;
- SQ逻辑比较Ack报文的PSN来确定属于以下哪种情况:
- Ack报文的PSN和最老的unAck的请求报文的PSN相等(本例为100);在本例中属于该情况,因此会把unAck的窗口的底端往后挪一个(本例为101)
- Ack报文的PSN>SQ的起始PSN但是比最老的unAck报文的PSN小,此时属于重复的Ack报文
- Ack报文的PSN比最老的unAck的请求报文的PSN大但是小于发出的请求报文的最高的PSN
- Ack报文的PSN小于SQ的起始PSN或者大于发出的请求报文的最高的PSN(意味这这是一个不合法的Ack数据包)
5. 发送’Send Middle’ 请求报文,然后Ack返回
需要注意的是请求方的QP的SQ逻辑在发送下一个请求包前不会等待刚刚发送的请求包的Ack
请求方QP的SQ逻辑会如下继续:
- 使用SQ顶端的条目,它会利用在SQ顶端的WQE的Gather Buffer List从内存中读取2KB数据
- 调整WQE的读指针
- 把PSN(101)放到”Send Middle” 请求报文中
- 把请求报文传给请求方的QP。它的opcode是”Send Middle”
在接收到请求报文之后,接收端的QP采取如下行为:
- 接收方QP逻辑比较请求包的PSN(这里是101)和它当前的ePSN(这里是101):
- 如果PSN=ePSN,那么继续执行
- 如果包的PSN>ePSN,那么RQ逻辑会给远端QP的SQ逻辑发送一个PSN Sequence Error Nak数据包,并且不会执行包请求的操作
- 如果包的PSN处于先前接受过的PSN范围内,那么RQ逻辑不会重新执行包的请求,但是会安排一个Ack返回;
- RQ逻辑会检查包的opcode来保证这是有意义的,比如这里应该是”Send Middle”或者”Send Last” 而不是”Send First”;
- 数据包的2KB载荷会根据顶端RQ WQE的Scatter Buffer List指针写入到CA的内存中;
- RQ逻辑会更新该指针;
- RQ逻辑更新ePSN到ePSN+1(102);
接收端的RQ逻辑会生成一个发向请求端的SQ的Ack报文,PSN与请求报文的PSN一致;如果这个Send操作有更长的信息就会重复上述动作;
6. 发送’Send Last’ 请求报文
请求端的QP的SQ逻辑继续以下动作:
- 利用在SQ顶端的WQE的Gather Buffer List从内存中读取最后1KB数据,放入包的载荷中
- 请求包的PSN是102
- 发送带有opcode为”Send Last”的请求包
在接收到”Send Last”请求包之后,接收方的QP的RQ逻辑执行以下步骤:
- 接收方RQ逻辑比较到来的请求包的PSN和ePSN,处理逻辑和上一节一致
- RQ逻辑会检查包的opcode来保证这是有意义的
- 数据包的1KB载荷会根据顶端RQ WQE的Scatter Buffer List指针写入到CA的内存中;
- 这个信息的所有数据包都被接受并且写入内存了,然后RQ逻辑会更新ePSN到ePSN+1,等待下一个信息的第一个请求数据包;
- 让RQ顶端的WQE“退役”,在RQ对应的CQ中创建一个CQE,包含了这个信息接受操作的状态;另外如果”Send Last”操作中包含了ImmDtETH(Immediate Data Extended Transport Header)信息,那么会在CQE中存储这个32-bit的数据
- 完成了对于这个信息的接受
- 当CQE发布到和任何QP的SQ或者RQ有关联的CQ的时候,CA会生成一个中断
7. 返回Final Ack
接收端的QP的RQ逻辑生成一个positive Ack包发送给请求段的QP的SQ逻辑;Ack的PSN(102)与”Send Last”请求报文一致;当Ack到达请求端的SQ逻辑的时候,SQ执行以下动作:
- SQ逻辑验证Ack报文的AETH字段确定它是positive Ack还是Nak,案例中是positive Ack
- 由于Ack “ack” 了”Send Last”请求报文,SQ逻辑执行以下动作:
- 让SQ的顶端的WQE”退役”
- SQ对应的CQ中创建一个CQE,包含了对于这个发送操作消息的完成状态
- 这就完成了消息发送操作;
传输类型
略
IB协议的信息传输操作介绍
发送消息的方式:IB网络中,消息传输的流程是:软件通过执行Post Send Request往请求方QP的SQ发送一个Work Request;
接受Send和RDMA Write With Immedaite的方式:接收方的软件需要通过执行Post Receive Request来往接收方QP的RQ发送一个WR;
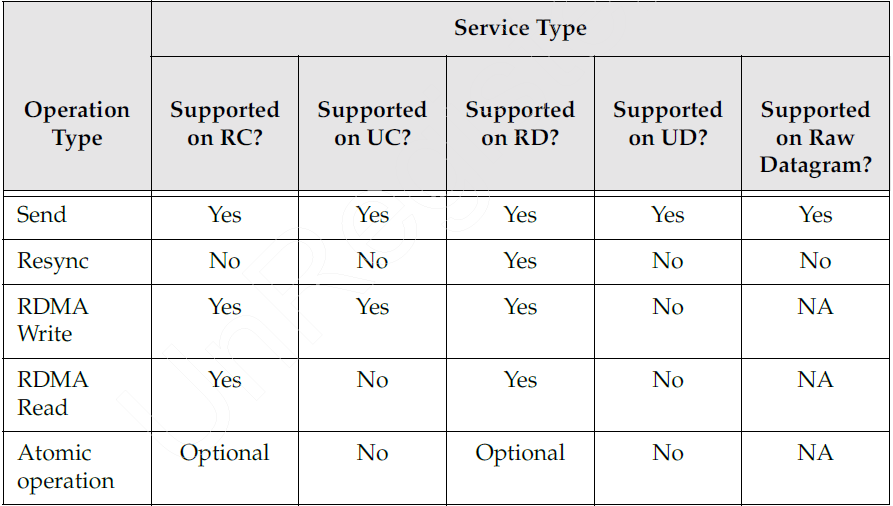
Send Queue(SQ)的操作类型有以下五类:
- Send:从本地指定内存中获取数据,发送给对端RQ,对端RQ顶端的WR将指示RQ接收的数据该存到哪块内存中;
该操作支持所有QP服务类型; - RDMA Read:SQ发起读请求,对端RQ接收请求后,读取指定内存中数据并返回,SQ接收所需数据后,写入本地内存;
仅支持RC和RD; - RDMA Write:将本地数据写到对端指定内存中(RDMA write和Send的区别在于,Send前往对端的数据是由RQ顶端的WR来决定数据的存放位置,但是RDMA Write是由发送方提前将存放位置确定并指示RQ的);
仅支持RC,UC和RD; - Atomic RMW:当某任务需要连续访问同一块内存时,需要保证在这期间禁止别的任务对这一内存进行修改,在IBA中,使用一个状态标志,表示内存数据是否处于不可修改状态;
- Memory Window Bind
- Send:从本地指定内存中获取数据,发送给对端RQ,对端RQ顶端的WR将指示RQ接收的数据该存到哪块内存中;
另外比较大的信息会被分片成多个数据包 ,因此传输一个信息的状态如下:
- 单个包
- 两个包:一个”First”,一个”Last”
- 三个及以上
- 一个”First”
- 大于等于一个的”Middle”
- 一个”Last”
BTH如下图所示:
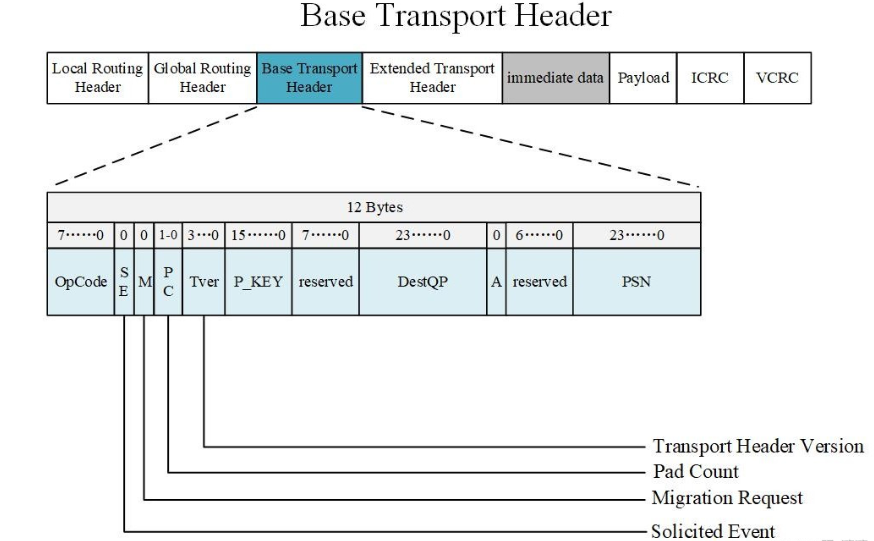
Packets Opcode 详情可见书81-84
SQ动词类型及操作
Send 操作
略
Read操作
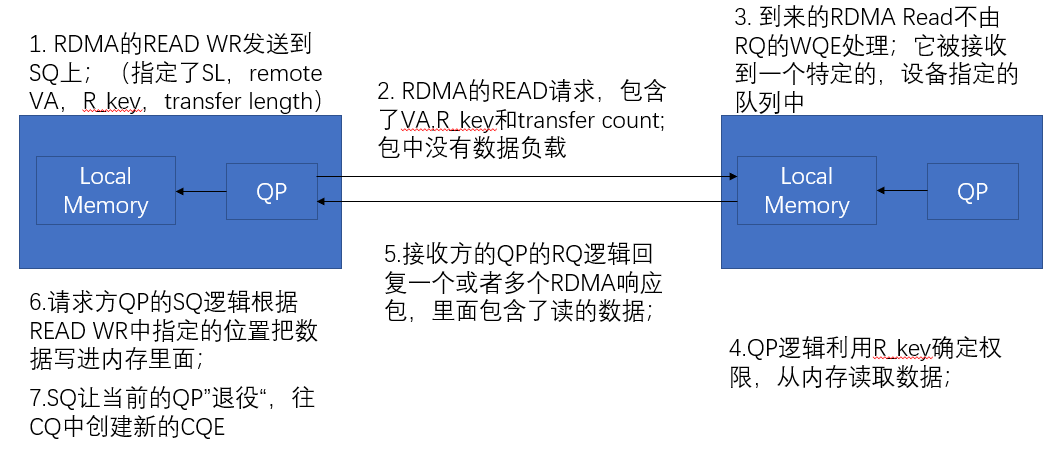
- RDMA Read操作是请求对端从内存读数据然后发回请求方,具体操作如下:
- 被读取方CA在本地构建一个信息
- 向SQ发布Send操作,CA通过软件向对端CA通知,本地信息已经可以读取;需要向另一个CA提供如下信息:
- 本地内存的起始virtual memory address(VA);
- Remote access key(R_Key),RDMA读权限(包含了区域长度以及该区域的权限,例如这里只能读不能写);
- 可被读取的数据大小
- 读取方CA接收到上述信息之后向SQ发送WR,里面确定了:
- VA
- R_key
- Scatter Buffer List ,用于指定内存buffer用于写入即将读取的数据;
- 要读取的数据大小
- 执行SQ WQE,SQ会携带3中的信息,组成RDMA read请求包;
- 对端RQ通过包中R_Key信息,验证该请求是否得到权限;
- 如果R_Key验证正确,RQ会从指定内存读取数据,并组成响应包返还给SQ;
- SQ收到响应包,并利用Scatter Buffer List将payload写入内存;
- SQ完成全部传输后,弹出WQE,创建一个CQE;
- PS:需要注意的是响应方的QP不需要往RQ里面发布一个WQE来处理READ请求
- 软件发布RDMA READ WR的时候需要提供以下参数:
- QP的handle
- RDMA read操作类型;
- Scatter buffer list以及其中的元素个数;其中的每一个元素都定义了本地内存的起始地址以及它的长度;
- 目标的相应QPN以及Q_key(RD使用)
- RC中不使用Q_key
- 相应的QPN存在请求方的QP中
- VA 虚拟地址
- R_key(Remote access key)
- 数据长度
- READ操作支持RC和RD
- 数据包内容:
- 请求数据包:BTH中有OPCODE,此时为RDMA Read Request;RETH(RDMA Extended Transport Header)中包含了VA,R_Key以及创数长度;数据包不包含数据载荷
- 响应数据包:
- 如果数据载荷小于等于PMTU,那么只会有一个RDMA Read Response包
- BTH中的Opcode:RDMA Read Response Only
- 数据载荷的大小是0-PMTU bytes;
- 相应包的PSN和请求包PSN一样
- 如果数据载荷可以放到两个相应包里面:
- 第一个包BTH的opcode是RDMA Read Response First;数据载荷包含了PMTU bytes,PSN和请求包的PSN一样
- 第二个也就是最后的请求包的opcode是RDMA Read Response Last;数据载荷大小是1-PMTU bytes;它的PSN比请求报文大一
- 如果数据载荷需要三个及以上的数据包
- 第一个包BTH的opcode是RDMA Read Response First;数据载荷包含了PMTU bytes,PSN和请求包的PSN一样
- 中间的包的opcode是 RDMA Read Response Middle;数据载荷包含了PMTU bytes,PSN比之前的包大一
- 最后的包的opcode是RDMA Read Response Last;数据载荷包含了1-PMTU bytes;PSN比之前的数据包大一
- 如果数据载荷小于等于PMTU,那么只会有一个RDMA Read Response包
- 另外,在发出请求之后,请求者QP的SQ可以发出额外的RDMA读请求(或其他类型的消息传输请求),不需要等待之前请求的读数据返回。但有一个例外:在RD服务类型中,SQ可能不会开始下一个消息传输,直到完全确认前一个消息传输。
- 如果响应端QP的RQ支持多个未完成的Atomic或RDMA Read操作,则它将接收到的每个请求按先进先出的顺序存储在特定队列中;FIFO的深度在连接建立阶段进行协商:
- 任何一次针对响应端QP的未完成RDMA读请求的最大数量在连接建立时协商;
- 响应端QP可以将一个连接限制为一个未完成的RDMA读请求,换句话说,这个队列的最小深度可能只有一个条目。
Write操作
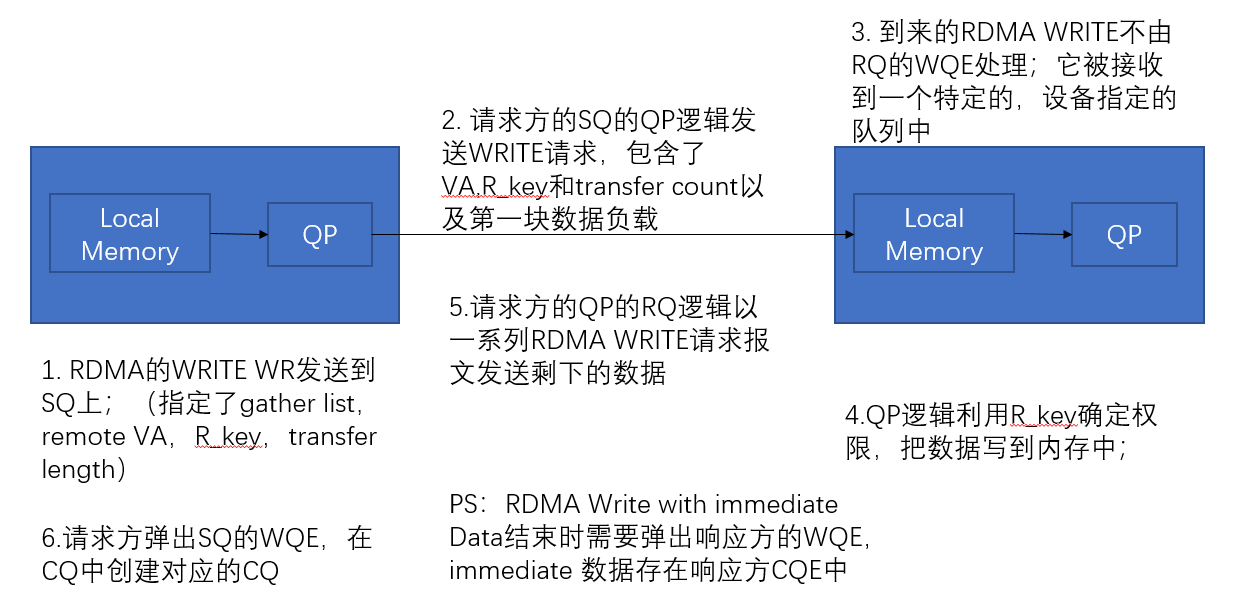
- RDMA Write操作是请求方逻辑向响应方内存通过RDMA Write request写入数据,具体步骤如下:
- 响应方CA预先准备好数据以及准备好访问这块内存的R_Key
- 通过Send操作,响应方CA把如下信息发送给请求方CA来告诉对方哪些区域准备好接受信息:
- VA
- R_key
- 内存区域长度
- 请求方CA接收到上述信息之后,发布RDMA Write WR到本地QP的SQ中,WR指定了如下内容:
- VA
- R_key
- Gather Buffer List,这里面指定了大于等于一个的本地内存buffer,里面包含了要SQ逻辑被读取的数据
- 要写的数据大小
- 可选的:32-bit immediate 数据项,这会放在信息的最后一个包的ImmDtETH中
- 请求方的SQ逻辑发起第一个RDMA Write请求报文到响应方的RQ逻辑;第一个报文包含了RDMA ETH,里面制定了VA,R_key,信息长度(最大2GB);另外如果整个信息包含在这一个包中并且WR指定了可选的32-bit immedaite数据项,那么此时的Opcode是RDMA Write Only With Immedaite,并且包含ImmDtETH头
- 到来的RMDA Write不由响应端的QP的RQ的WQE处理,而是RQ逻辑把它发布到一个特定的,设备相关的队列中
- 响应方使用R_Key鉴权
- 如果鉴权成功,那么响应方的RQ逻辑会把数据载荷写入本地内存
- 如果是多个包的信息,那请求方的SQ逻辑会发送剩余的包,响应方的RQ逻辑随之完成对内存的写入
- 在整个完成的时候,如果最后的包含了ImmDtETH,那么这32-bit的immediate data会存在CQE中,响应方QP会弹出RQ中的WQE创建CQE,
- RDMA Write除了RDMA Write With Immediate Data之外不会使用RQ的WQE;
- RDMA Write支持RC RD 和UC
- 数据包内容:
- 请求数据包:
- 单个数据包RDMA Write操作
- 整个信息包含在数据负载中,包含了0-PMTU bytes数据
- Opcode是RMDA Write Only或者RDMA Write Only With Immediate
- 数据包在RETH包含了VA,R_Key以及传输长度
- 两个数据包RDMA Write操作
- 第一个包的opcode是RDMA Write First;数据载荷包含了PMTU bytes数据;数据包在RETH中包含了VA,R_Key以及传输长度
- 第二个包的opcode是RDMA Write Last或者RDMA Write Last With Immedaite;数据载荷包含了1-PMTU数据
- 三个及以上数据包RDMA Write操作
- 第一个opcode是RDMA Write First;数据载荷包含了PMTU bytes数据;数据包在RETH中包含了VA,R_Key以及传输长度
- 中间的包的opcode是RDMA Write Middle;数据载荷包含了1-PMTU数据
- 最后一个包的opcoed是RDMA Write Last或者RDMA Write Last With Immedaite;数据载荷包含了1-PMTU数据
- 单个数据包RDMA Write操作
- 请求数据包:
- Immediate Option的用途:
- RDMA Write实际上在结束的时候在发送方会产生CQE,如果有immediate option会在接收方产生CQE,进入通知软件已经完成了写入
- 另外immediate可以用于表示这块信息的来源
Atomic RMW 操作介绍
该操作可以用于信号量,锁等并发场景;
两种原子RMW操作类型
- FAA fetch and add
- CaS compare and swap
每一种操作都包含了一个请求包和一个Ack包;这两个包都没有数据载荷,相关数据存在ETH头里面;
准确的说此类请求包都包含一个AtomicETH field,里面包含了如下元素:
- 四字对齐的该信号量的虚拟地址
- R_key,需要保证有读写权限
- 修改的值(Add_data或者CaS_data)
另外,响应包中带有AtomicAckETH,里面包含了信号量在更新之前的数据;
原子操作额外的操作特性:
- 如果CA支持RMW操作,那么CA能够处理的未收到的请求数量是在连接建立阶段协商的
- 当接收到原子操作请求报文的时候,响应方的QP的RQ会把它发布到用户相关的队列中
- 标准建议原子操作的实现由硬件达成
- CA的实现可以选择性的保护RMW相关的内存与其他CA,IO设备以及CPU的原子性;
- 原子请求包的VA必须是四字对齐的,否则会返回一个Invalid Request Nak.
原子操作
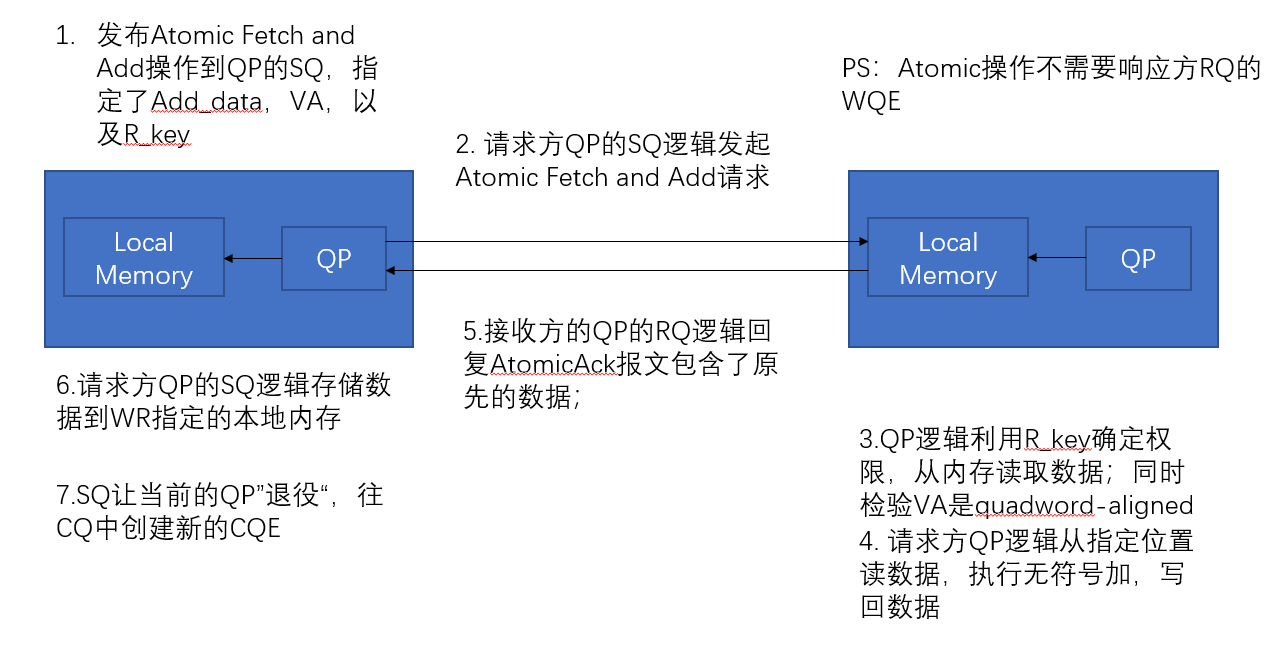
Atomic Fetch and Add 操作
FaA操作需要响应方的QP的RQ执行以下动作:
- 根据
虚拟地址/8这个位置,读取64-bit数据 - 根据报文中的AtomiETH字段的64-bit Add Data字段,执行无符号加法
- 把结果写回到先前的位置
该操作需要具有原子性;
请求方需要在请求报文中指定:
- 远程数据地址,R_key
- 要加的数据
响应方会返回该信号量修改之前的原始数据
- 根据
具体流程如下图:
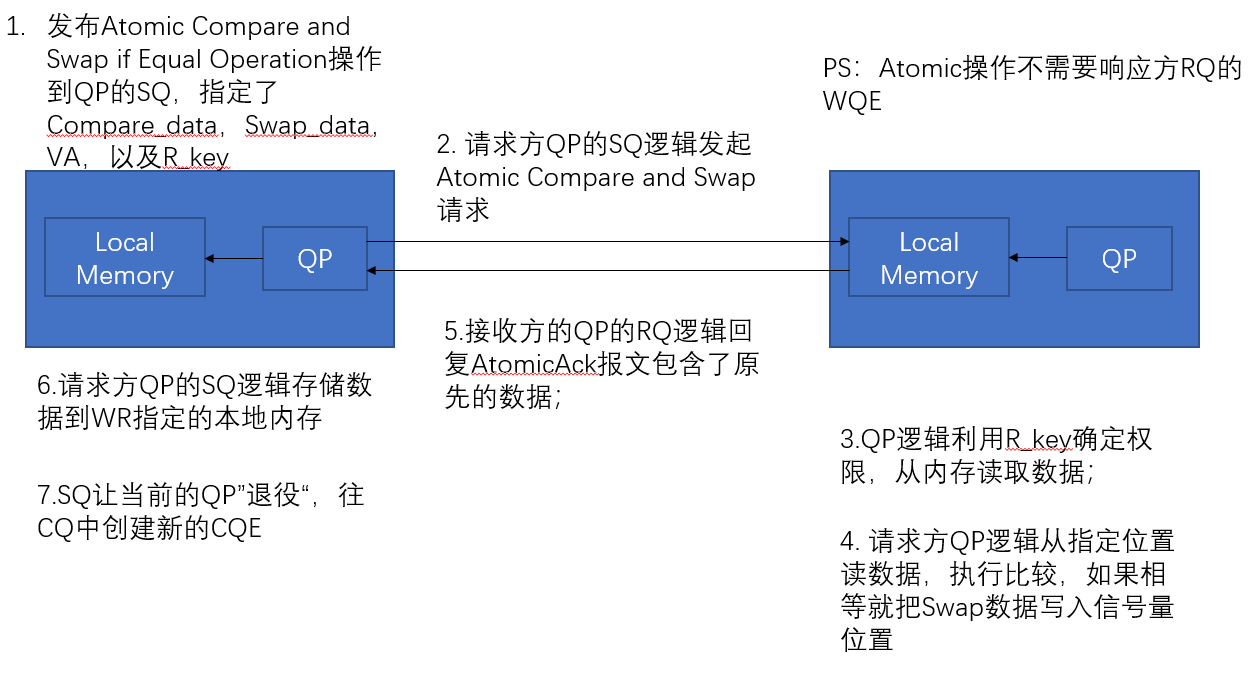
Atomic Compare and Swap if Equal Operation 操作
Cas操作需要响应方的QP的RQ执行以下动作:
根据
虚拟地址/8这个位置,读取64-bit数据把该值和AtomicETH中的Compare Data field中的64-bit值作比较
根据比较结果做出如下动作:
- 如果相等那么把AtomicETH中的Swap data写入到信号量的地址
- 如果不相等,那么不会改变信号量;
然后会把信号量原来的值返回给请求方逻辑;
请求方需要在请求报文中指定:
- 信号量的起始地址VA
- R_Key
- 64-bit Swap data
- 64-bit Compare data
上面的Swap data,Compare data,以及原先的值都是在包头传输的,并且是big-endian format;在响应方的读写以及返回的数据的存储都是native endian format的;
具体流程如下图:
Bind Memory Window 操作
这部分与memory protection有关;主要作用是把先前创建的内存窗口和先前创建的内存区域关联起来,用于定义访问权限;不会导致任何的包传输;
具体流程是首先创建region和window,然后软件发布一个Bind Memory Window WR到SQ上面;WR指定了:
- Region的handle
- Window的handle
- R_key
- window的起始VA和长度
- 对于请求方QPs的权限s;
通过对于该WR执行Post Send Request动词会返回与这个窗口相关的R_key;
SQ操作与服务类型
RQ动词操作
往RQ上发布WR可以处理:
- Send操作
- RDMA Write With Immediate 操作
通过执行
Post Receive Request动词来发布WR,WR执行以下功能之一:- 通过Scatter Buffer List来确定到来的Send数据写入的位置
- 通过一个没有Scatter Buffer List的”假”WR来接受RDMA Write With Immediate的immediate数据
WR中指定的VA的范围应该在软件在本地QP中创建的地址空间内;
RQ对于Send操作的处理:
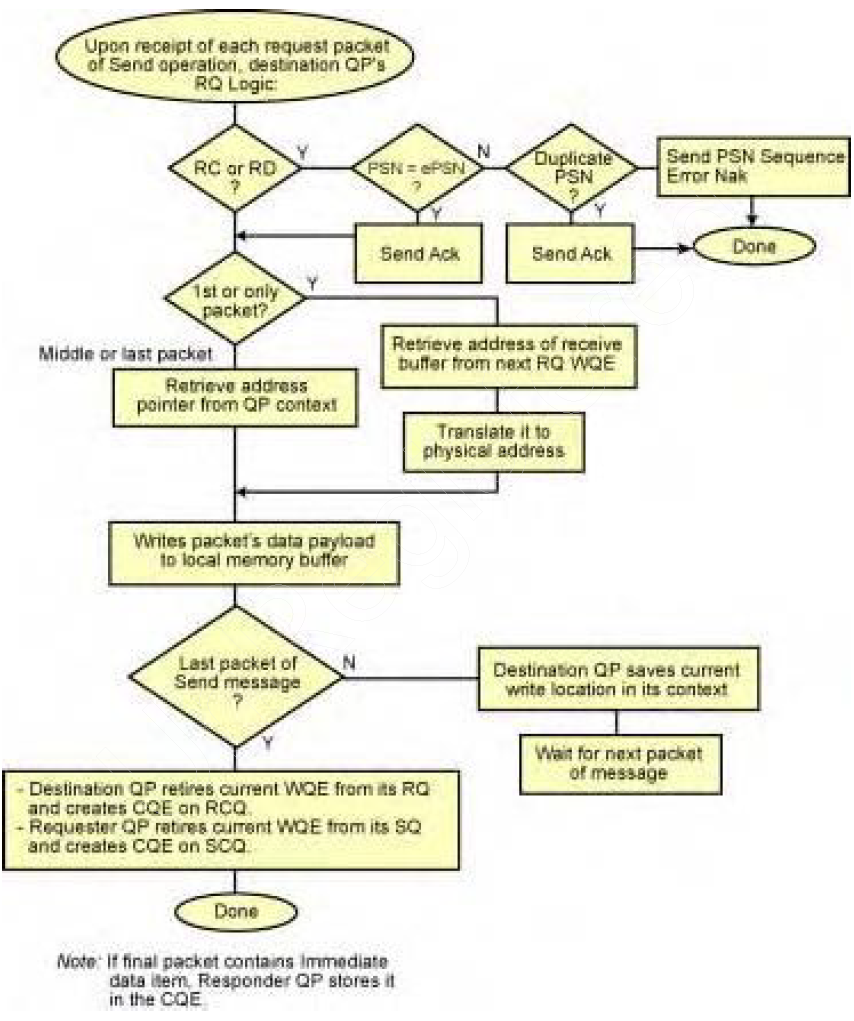
如果没有RQ WQE处理的化,接收方会返回一个Receiver Not Ready Nak;
