p4学习-5:完善MRI
实验目标
这次实验的目的是在基本的L3转发上面拓展一个带内遥测(INT)的阉割版本,这里称作多跳路由检查(Multi-Hop Route Inspection)(MRI)。
根据维基百科,多跳路由(Multi-hop routing)是无线电网络中的一种通信,其中网络覆盖区域大域单个节点的无线电范围,因此要到达某一个目的地的时候一个节点可以使用其他节点做中继。
MRI允许使用者追踪每一个包经过的路线以及序列的长度,为了支持这个功能需要写一个P4程序,这个程序能够在每一个包的header stack上面附加一个ID以及队列的长度。在收包的目的地,交换机ID的顺序相当于这个包走的路径,每一个ID后面都跟着这个交换机的队列长度。
控制平面已经事先设置好了
代码实现
mri里面包括了两个自定义的头:mri_t包含了count,用来指示交换机ID的数量;switch_t包含了数据包经过的每个交换机跳的交换机ID和队列深度字段;
主要挑战是处理用于解析两个headers的递归逻辑;这里使用parser_metada字段的remaining来追踪有多少switch_t头需要来解析;在parse_mri状态,这个字段设置为hdr.mri.count。在parse_swtrace状态将转换到其自身,直到剩余为0。
MRI自定义报头会携带在IP Options 头里面,其中IP Options头里面的option用于指示选项的类型。 我们将使用特殊的类型31来表示MRI标头的存在。
除了解析器逻辑外,您还将在sgress中添加一个表,在swtrace中存储交换机ID和队列深度,并执行增加count字段的操作,并附加一个switch_t标头。
一个完整的mri.p4包含如下组件:
- 以太网(
ethernet_t),IPv4(ipv4_t),IP选项(ipv4_option_t),MRI(mri_t)和交换机(switch_t)的header头部类型定义。 - 以太网,IPv4,IP选项,MRI和交换机的解析器Parsers,将填充
ethernet_t,ipv4_t,ipv4_option_t,mri_t和switch_t。 - 使用
mark_to_drop()丢弃数据包的动作action。 - 一个action动作(称为
ipv4_forward),它将:- 设置下一跳的出口端口。
- 用下一跳的地址更新以太网目标地址。
- 用交换机的地址更新以太网源地址。
- 减少TTL
- 一个ingress control:
- 定义一个表,该表将读取IPv4目标地址,并调用
drop或ipv4_forward。 - 一个应用表的
apply模块
- 定义一个表,该表将读取IPv4目标地址,并调用
- 在egress部分,将添加交换机ID和队列深度的action动作(
add_swtrace)。 - 一个egress control,它应用表(
swtrace)来存储交换机ID和队列深度并调用add_swtrace - 用于选择将字段插入传出数据包的顺序的deparser。
- 实例化
headers部分
1 | /* -*- P4_16 -*- */ |
实验过程
1 先跑不完整的初始版本代码
先跑一下初始代码看看啥样,以便和之后的做对比
在shell上面跑:
make
这步会:
- 编译
mri.p4 - 启动一个 Mininet 实例,其中三个交换机(
s1,s2,s3)设置在三角形结构里面。有5个主机.具体见拓扑图部分 - 主机被指定成了
10.0.1.1,10.0.2.2,其他的也都是(10.0.<Switchid>.<hostID>)这种格式 - 控制平面部分的规则是基于
sx-runtime.json
- 编译
准备做的事情是在
h1和h2之间发送低速率的流, 在h11和h22之间发送搞俗的测试流。s1和s2之间会形成一个拥塞因为在topology.json里面把带宽削减到了512kbps。因此如果我们在h2收包胡发现连接里面有很长的队列等待长度。拓扑如下:
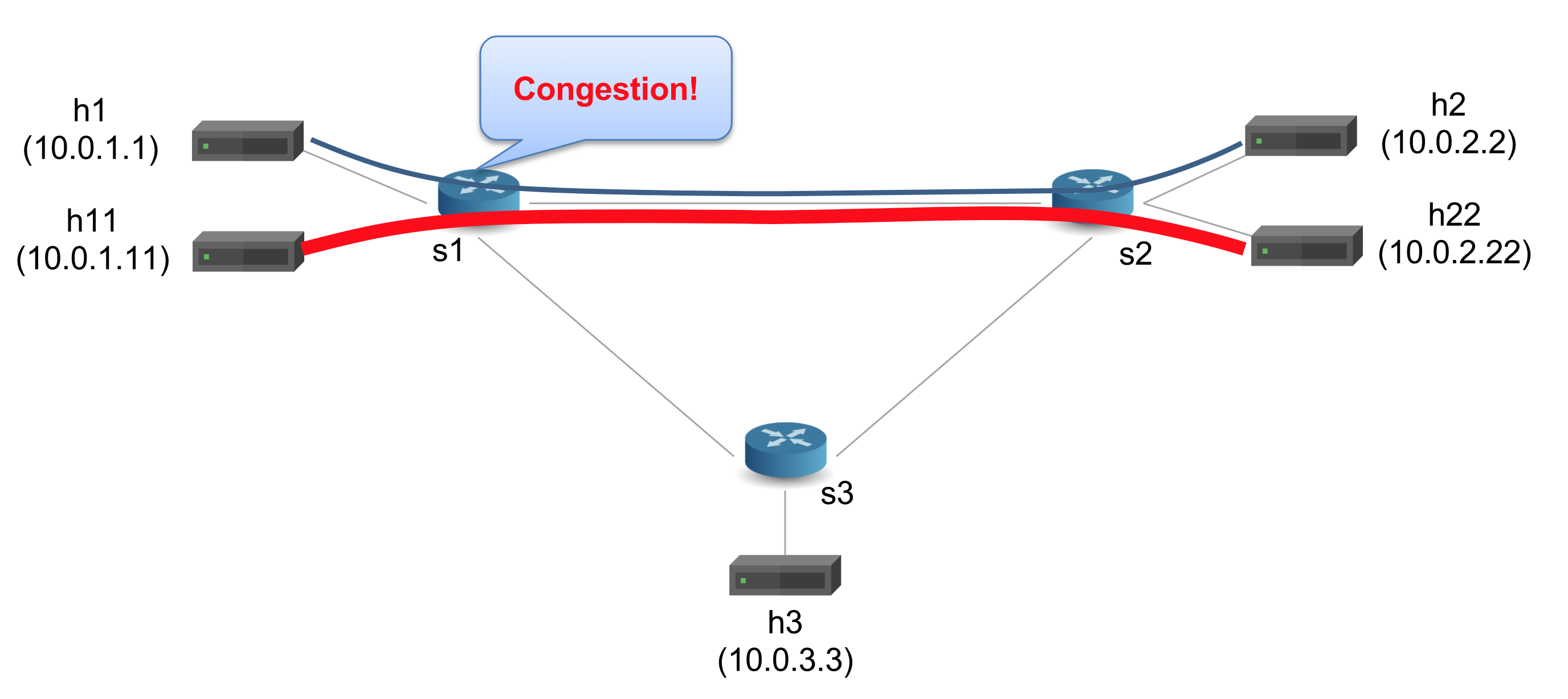
在make打开的Mininet命令行界面开四个窗口:
1
mininet> xterm h1 h11 h2 h22
在h2的xterm里面打开收包的服务:
1
./receive.py
在h22的xterm里面打开iperf UDP 服务:
1
iperf -s -u
在h1的xterm里面使用
send.py给h2每秒发一个包,发30秒:1
./send.py 10.0.2.2 "P4 is cool" 30
在h2的xterm里面会收到”P4 is cool “信息
在h11的xterm里面,启动iperf客户端发送15秒:
1
iperf -c 10.0.2.22 -t 15 -u
在h2端,MRI header没有hop信息(count=0)
退出来
这里h2虽然接到了信息,但是没有关于这条消息经过的路径的信息。完善的内容就是在
mri.p4里面完善MRI逻辑来记录路径信息。到目前的实验结果如下:
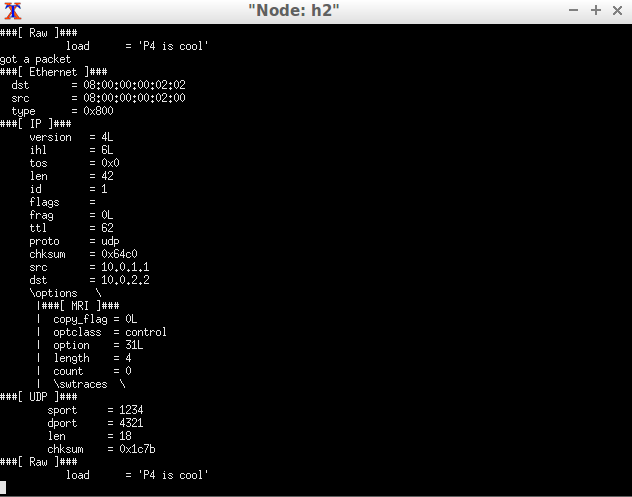
会发现h2收到的MRI信息里面的count=0;
h22中因为线路的带宽有限,几次实验发现15秒发不完:
h1和h11里面是发包的提示信息:
h1如下:
h11如下:
2 控制平面相关
控制平面相关:P4程序定义了一个数据包处理管道,但是控制数据包的规则是由控制平面插入到管道中的。 当规则与数据包匹配时,将使用控制平面提供的参数作为规则的一部分来调用其动作。在本练习中,控制平面逻辑已经实现。 作为启动Mininet实例的一部分,make脚本将在每个交换机的表中安装数据包处理规则。 这些定义在sX-runtime.json文件中,其中X对应于交换机号。
1 | //s1-runtime.json部分代码 |
不难发现这里的表项和拓扑图以及P4代码里面的table息息相关,写法也和之前的P4runtime里面的相似
3 完善MRI
见前面的代码实现部分
